

Results, Actually
A loose ensemble of disjointed storylines.

For the last three years, I’ve periodically asked people to respond to a number of silly surveys. And for the last three years, I’ve kept those results to myself. Time to repay those debts.1
Happy holidays, and thanks to everyone for reading along.
VC Fantasy League
When I first started this blog, this is what I said it’d be:
Expect predictions about data technologies and observations about corporate data culture alongside the regularly scheduled commentary on Pitbull. (Or, if you’re here for the tech stuff, consider this a warning that you’ll have to put up with posts on Pitbull. Either way, there will be Pitbull content.)
Neither turned out to be true. The Pitbull thing is my Winds of Winter, and all of the promised posts about data technologies devolved into rants about how data is a Ponzi scheme, a fad, an industrial complex, and not a career.
Evidently, however, this is not a popular opinion. A while back, I asked people to choose which of these five companies they’d invest in:
One led by experienced industry veterans.
One led by ruthless operators.
One led by a generationally-talented prodigy.
One led by people who shipped quickly and constantly.
One led by data.
Over at benn.ventures, our ranking would’ve been talent, experience, speed, operations, and, in dead last, data. But here at benn.substack, 180 readers’ rankings were very different:
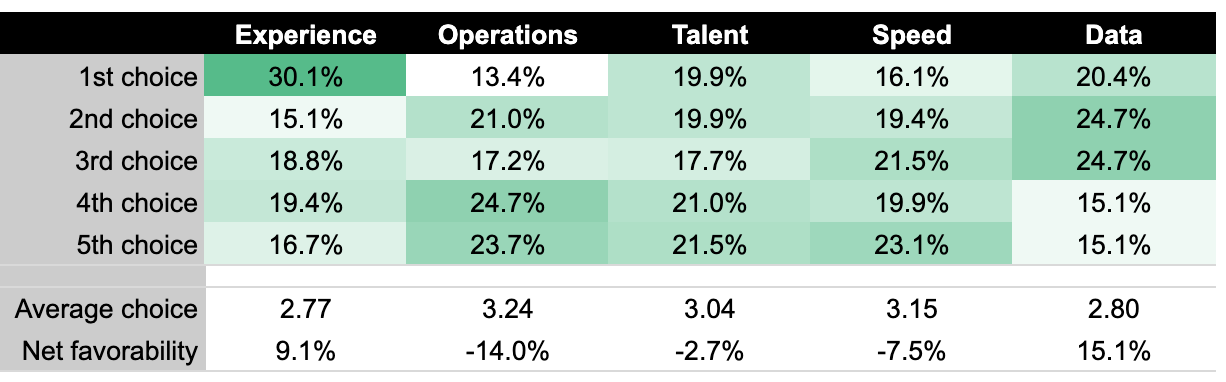
The experienced company has the best average ranking, and the data-driven company has the highest net favorability score (i.e., first plus second choices minus fourth plus fifth choices). People have very mixed opinions on talent, they don’t love speed, and operators are the clear losers.
A rough tie at the top, then. But ties are unsatisfying. So, how do people rank the two top attributes—experience and data—directly against one another? Sure, 30 percent of the respondents said that the experienced company was their first choice compared to 20 percent for data-driven company, but what percent of people would rather invest in the data company over the experienced one, regardless of how they score the other three companies?
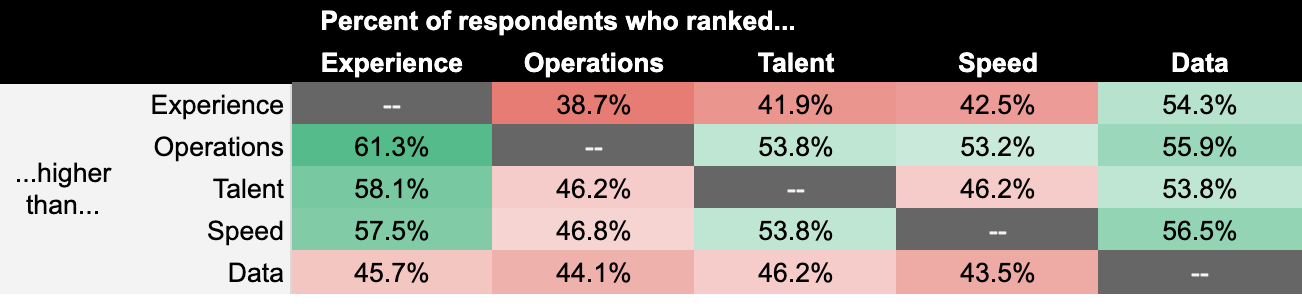
The data company wins every head-to-head matchup. If only two companies walked into the door of our collective VC office—instead of five at once, which is how the original question was framed—the data company would walk out with the term sheet every time.
Which, great, you can have it. Better terms for benn.ventures’ contrarian bets on talent.2
Contrarians
Speaking of, a few weeks ago, the internet revolted against Spotify Wrapped, for two reasons:
The “insights” were weird. Instead of telling us what genres we liked or which albums we listened to the most, Spotify instead fed a bunch of meaningless AI-generated memeslop. We didn’t listen to rap music with some occasional bouts of country; we were a Pink Pilates Princess who liked Hollywood Pop. It was as if the famous New York Times dialect quiz stopped saying we were from Montgomery, Alabama,3 and instead told us that we spoke like Cornfield Clarinet Girlies.
Even worse, it called us basic.
Because the only thing we want to know more than what we listen is that what we listen is was cool. We want to be different. We want to know that, while everyone else is listening to Drake, we are tastemakers; original thinkers; contrarians, with an exquisite palate.
Anyway, a year and a half ago, I asked the readers of this blog to prove your contrarian bona fides. Pick a number between 1 and 20, I asked, with the goal of choosing a number that would be chosen by the fewest other people. Nobody wants to be the same as everyone else; prove that you aren’t.
Here are the results. It’s time for some game theory:

Sixty-three people voted legally; three people cheated;4 zero people won. Because, oops, it turns out the contest was unwinnable: The winning numbers—6, 8, and 15—got no votes; had anyone voted for one of them, they would’ve no longer been winning numbers.
Still, three numbers were only chosen by one person each, which is pretty close to winning. So congratulations to the three readers who chose 9, 11, and 16—you are this blog’s best game theorist and its most promising influencers.
Of course, influencers need the influenced—the masses, the mainstream, the lemmings who march to whatever generic beat Spotify’s algorithmic drum beats out. That’s you, whoever chose 1, 10, and 17. I am sorry, but your number wasn’t a banger of a B-side from the back of a Shoreditch record store. It was Drake. Oh well.
But that wasn’t the only question the survey asked. It also asked everyone to guess which number they thought would be chosen the most. Because being a contrarian only gets you so far. To be a true trailblazer, you also have to have taste, and know what other people like.
And people are surprisingly good at that? People predicted that 1, 7, and 17 would be the most popular answers to the first question; 1 and 17 were, in fact, the two most popular answers.5 In total, the average answer to the second question was the seventh most popular guess to the first question.6 Though people really overestimated the popularity of 7:

This second question also offers a way to break the tie among the three best answers to the first question. Who didn’t just pick an unpopular number, but also predicted what everyone else would choose? We have a winner:

Congratulations to Voter #11—coincidentally, they were both the eleventh response and the only person who voted for 11—who left this comment with their response:
this actually hurt my brain, I'm embarrassed to admit how much time I spent on this meaningless activity.
Meaningless then, perhaps, but historic now. You are our champion. Our Rick Rubin. Our Kim Kardashian. You know us better than we know ourselves. Expect an email, Voter #11, and a major award.
And to the rest of you, keep pumping those Sabrina Carpenter streams. Somebody gotta do it.
Robots
To me, an almost geriatric millennial, R2-D2 is a robot. C-3PO is a robot. Wall-E is a robot. Alexa, Siri, and ChatGPT are not. They are disembodied search engines, a spell checker attached to a phone speaker. An immobile piece of glass is not a robot; robots are full of grease and gaskets and little blinking eyes that tell you they are on.7
But what is a robot to a different generation? To a Boomer, is it a toaster oven with a timer? To Gen Z, is it the entire opaque machinery of Doordash? Does Gen Alpha even use the word at all, or has it been replaced by some incomprehensible TikTok slang? I had to find out.
Lots of you think R2-D2 is a robot; fewer of you think of C-3PO. The youths think of the Terminator, which is a little weird; the boomers think of Robby the Robot, which makes sense.

But the strangest answer is HAL. The movie character HAL was created over 50 years ago.8 The fictional HAL—the thing created in 2001, when HAL went on its space odyssey—is 23 years old. That’s older than “Hot in Herre,” and “Complicated,” and “The Middle”! That’s old!9 Why is that the third-most popular robot for 20-year olds?
Gen Z, man.
Microsoft Excel
I have no idea what it says that people think that:
the NFL is more durable than American democracy, and
Google will outlast the iPhone, and
Tesla will outlast Google, and
JPMorgan will outlast all of them (including American democracy), and
all living creatures are only slightly more likely to survive the next fifty years than Microsoft Excel
but that is evidently what people think.

Of course, another thing that people think—from the same survey; I don’t know; it made sense at the time—is that “A Whole New World” is the best song from Aladdin, and that “One Jump Ahead” is the worst. So sometimes people get things wrong.

Mailbag
Some people included questions in their survey responses. Other people left them on the most recent addition to the benn dot empire,10 benn.gripe. These are some of those questions.
———
Aren’t analytics engineers just…data engineers that don’t really use Python (and use dbt instead)? Why all the rigamarole?
Many people are saying:
I’ve long held that creating the “analytics engineer” role was a mistake. dbt Labs says, “Analytics engineers provide clean data sets to end users, modeling data in a way that empowers end users to answer their own questions.” I don’t believe that this set of activities is enough value to justify a full headcount; it’s too limited in scope and too far removed from revenue generation.
I don’t know; cleaning data and making it useful is famously hard work. If we assume that that cleaned data is valuable, then it certainly seems like dedicating a role to that task is worth the cost. This is especially true given how analysts often work: They are constantly building in pseudo-production, creating new appendages on top of core data systems that are designed to answer some unspecified set of questions for some unspecified amount of time. It gets unwieldy in a hurry, and it’s useful for somebody to be responsible for keeping the underlying architecture sane. Someone needs to define and maintain production, and the analysts who are frantically updating a slide in the middle of a board meeting aren’t going to do it.
People may say, sure, but that’s the job of a data engineer. And maybe it should be. But here’s the problem:
Over the last decade or so, we’ve created a lot of tools that make it easy to build basic data pipelines in SQL and drag-and-drop ETL tools. These tools are good enough for most companies to do most of what they need.
Data engineers (also famously) don’t want to build basic data pipelines in SQL and drag-and-drop ETL tools. They are engineers, after all, and want to build real applications with real code. If you hire a data engineer and tell them to babysit Fivetran, they will be upset.
So how do you signal to the data engineers you want to hire that they will be doing the job of cleaning data, but will be doing it with SQL and drag-and-drop ETL tools? You…give that role a different title?
In other words, the nature of data engineering has changed (or expanded), in a way that’s generally unfavorable to data engineers. In that context, I think analytics engineering is useful, not because it represents a distinct responsibility from data engineering, but because it’s a way to describe the methods through which the data engineers are expected to do it.
———
Product management is overrated.
…and…
Do data teams feel like they are more part of product or finance?
Matt Levine has this bit: Everything is seating charts. Above all else, the richest people on Wall Street—the masters of the universe, people who can buy 122 million dollar mansions after thinking about it for 15 minutes—care about which clubs they’re in, and how important they are relative to everyone else in the club. A better seat, a better seat, my literal, actual kingdom, for a better seat.
Anyway, tech employees aren’t all that different. Data teams ostensibly want to be in the rooms where decisions are made to influence those decisions, but the real motivation is probably more direct: Being in the room is the whole point. It is its own ends. A few people want to be important to mold the world into some favored shape; most people just want to be important.
Culturally, data teams are probably more aligned with finance teams than product teams. Both are reactive bean counters who want to be more proactive “strategists;” both quietly relish saying no, telling people to be realistic, and policing other people’s logical reasoning; both count stuff.
But in Silicon Valley, “the builders” are important. Product teams and product leaders make the fun decisions, and get celebrated as visionaries. “Who is the best series C CFO right now?” is, at best, niche engagement bait on Twitter. So data teams reject their natural allies, and try to sit at the product table.
———
I don't like C-3PO.
See, this is why I think R2-D2 was more popular. He’s a lovable sidekick, and C-3PO is more of an annoying tagalong, in the way as often as he is useful. I do sometimes wonder though—why is Jar Jar Binks seen as a historic cinematic mistake, but nobody is particularly bothered by C-3PO? (Case in point: “I don't like C-3PO” is a mildly hot take.) They’re functionally the same character: Both are bumbling klutzes who occasionally stumble into being a hero. Both are more slapstick stooge than warring spaceman. Both are clumsily rendered—Jar Jar Binks in bad CGI; C-3PO as a man in a stiff metal suit, a mannequin in shining gold armor, the little brother from A Christmas Story who can’t put his arms down. And yet, one is on lists of the greatest movie characters of all time, and one is on lists of the worst.
I’m not convinced that had Jar Jar Binks been in A New Hope, and a new doofus of a droid been in A Phantom Menace, our opinions of them would also be reversed. In the 1970s, hammy comedy seemed to play. Steve Martin sold out arenas with an act full of goofy props and silly catchphrases. Today, that kind of bit feels juvenile. But by the time we soured on it, C-3PO was already written into the hall of fame.
———
Do you have any Darvin Ham opinions?
Ron Gant hit titanic foul balls. Shaq was lights out from the free throw line in practice. Darvin Ham is 14-0 in NBA Cup games. Sometimes, the problem isn’t the player; the problem is the yardstick.
———
Why is your LinkedIn account one week late on your essays?
The professional writer finishes their pieces the day before they are due. They work with an editor to refine them, polishing, fact-checking, pruning. They publish on time, and then diligently share their work across different social media channels, posting catchy threads on Twitter that are engineered to spark conversation and engagement. They post on LinkedIn, TikTok, Bluesky, Instagram. They know that distribution matters as much as production, and they put in the work to do both.
The coffee shop Substacker crash lands unedited blog posts at random on Friday afternoons. By the time the piece is done—which has more to do with running out of time than with arriving at any sort of coherent rhetorical destination—he’s sick of reading it, so he immediately closes his laptop and wanders off aimlessly down the street. Eventually, he remembers to tweet something, though it’s often a messy non sequitur that he justifies by saying that that’s the whole bit, even though the bit is a tired snowclone that probably should’ve been retired years ago.
Eventually, he realizes that the piece isn’t doing numbers, and that his fragile ego needs more likes. But it’s 5pm, and his fragile ego also can’t handle being the guy who’s posting on LinkedIn on Friday night. So, he waits until Monday. And by then, someone has usually blown a hole in the original article, so the LinkedIn post can’t just be an AI-generated twist of the blog post; it has to be some back-heeled misdirection that the piece isn’t about what it was about.
———
You should join Bluesky! Then you can have fun nerdy convos....not on LinkedIn. It's like Twitter from a decade ago, only better, I promise.
…and…
Can you email me a secret search term that I can use to find your shit-post alter-ego on Bluesky?
My fragile-ego Bluesky: benn.blue.11
My alter-ego Bluesky: It’s too many options.
———
I'd like to address that universal semantic layer...
I'd propose that in addition to the semantic layer sitting on top of the shared source of truth that has been ETL'd from all of the raw data through all the technical operations and, more importantly, all of the business rules—it needs to be augmented. We need the most brilliant analysts, to also have access to every field in every table of raw data (and we need to keep that data outside of the OLTP apps it came from), together with a complete definition of every column and every table, with any tool that is SQL compatible. To have the freedom, you can't have the governance, the shared, the single version of truth, the thousands of business rules, the limiting tool on top of them—you must also have access to fully defined raw data.
What is raw data? I suppose you could have two answers:
It is whatever data is collected at the source. In 1900, raw data on major league pitchers was data on the result of every at bat. In 1980, it was pitch-by-pitch data, and the result of each pitch. In 2024, it’s by-the-millisecond data on pitch velocity, location, and spin rate. In other words, raw data is relative to what’s available.
It is an absolute definition of granularity. In 1900, pitchers didn’t have raw data. In 1980, they did. In 2024, they have raw data and then some.
I don’t think the second answer makes sense. But if the first answer is correct—that raw data is the most granular data that’s available—then what happens if you simply redefine “available” as what’s been processed by a semantic layer?
For example, suppose you collect by-the-millisecond pitch data, and transform that into pitch-by-pitch data. Do people have access to raw data? No, probably not. Do people need access to raw data? Well! Did they need spin rates in 1980?
My sense is that analysts are to raw data as everyone else is to self-serve. We want it more than we’d actually use it. Unlimited freedom sounds great, until we’re presented with a blank page and told to write. We need the prompts and constraints. Boundaries may limit us, but the infinite paralyzes us—and we are often better off accepting and making the most of what we have than we are spending our time trying to get more of what we don’t have.
We may hate the guardrails, but we need them. We need to live in a world that has those walls. We weep about them, but we have that luxury. We don’t actually want raw data because deep down in places we don't talk about, we want those walls, we need those walls. And those walls have neither the time nor the inclination to explain themselves to people who rise and sleep under the blanket of safety that they provide, and then question the manner in which they provide it.
(Which is all to say, sure, I think semantic layers shouldn’t be so restrictive that they roll everything up into a bunch of daily aggregates or something. But I don’t think people need whatever event stream the machines spit out either. There is some level of granularity that balances this correctly, and it could sit on either side of a semantic layer.)
———
The thing is even if the genie [from Aladdin] owes you a lifetime of favors [after you wish them free], you have no guarantee on what personality traits the genie may have. Even if a promise of a "lifetime of favors" is offered, there's always the case where the genie ditches you after they’re free.
…and…
There is a difference between the product and the brand name—one can persist while the other changes. The fact you can get more wishes from freeing the genie is the point—you gain more by not enslaving him.
Every remake of Aladdin tells the story in more or less the same way: Aladdin falls in love; he befriends a genie; the two defeat Jafar; Aladdin gets the girl; he frees his friend. But now I want a new version, told as a game of cat and mouse between Aladdin and the genie. The genie is trying to ingratiate himself with Aladdin so that he sets him free; Aladdin is trying to figure out if giving the genie his freedom will win him a lifelong magical friend, or if he’s just getting played.
The real housewives of Agrabah; somebody gotta do that one too.
———
Freeing the genie actually reduces their power. The lamp is a coercive force that takes something from the user and then refines and condenses the imprisoned djinn's magical energies (which is why you only get three shots). Freed from the lamp, the djinns return to being just playful spirits.
This, plus Jafar’s plotline, seems like it creates another possible scheme to get essentially get more wishes. Jafar asked the genie to make him the most powerful sorcerer in the world. His power is second only to the power of the genie—who derives that extra power from bondage of the lamp. So, it seems like you can do this whole thing in two wishes:
Wish to be the most powerful sorcerer in the world.
Wish to free the genie.
Like, when Aladdin negged Jafar by saying “ah ha, but the genie is still more powerful than you,” what if Jafar had then said, “good point, I’ll set the genie free”? Would the two have been locked in some eternal cosmic struggle? Is a reduced genie still more powerful than a sorcerer? Would the Jafar become the de facto genie of the world, without the shackles? What would’ve happened then?
It might be time for me to find a job, y’all.
Well, most of those debts. I still owe people results—and one person some slippers—for their responses to my question about finding insights.
The hypothetical companies in this survey were fashion companies, so I also asked who should be my fashion icon. Answers included Ben Simmons, BTS, Dora the Explorer, Harry Styles (x3), Larry David (x2), Lewis Hamilton (x2), Post Malone, Selena Gomez, Steve Aoki, Ted Lasso (x2), Travis Scott, Vitalik Buterin, Warren Buffett, Yves Saint Laurent, Zendaya, and anyone wearing crocs.
According to the AIs, here’s what that outfit should look like.
{kind=link}
I am not, but Greensboro is close.
They chose numbers like 21 and 1.983475435. This is why we can’t have nice things.
17, it’s always 17.
Somewhat interestingly, the people who were good at the first question weren’t any better at the second question. Twenty people picked one of the least popular ten numbers in their first answer; those people chose, on average, the 7.35th most popular number in the second question.
Blinking, not breathing. Breathing was creepy.
To be fair, it’s barely older than this survey, which was from June of 2022.
Food $200
Data $150
Rent $800
Gimmick benn dot domains $3,600
Utility $150
someone who is good at the economy please help me budget this. my family is dying
Ibid.
The "disjointed" Universal Semantic Layer section was 100% JOINTED for me. I'm an in-the-trenches business owner of "the data" at a NYSE company in an industry that's two decades back in a time warp. I got handed "the data" because I've been helping connect all the systems for the last 15 years and know the whole thing end-to-end. This section was 100% spot-on...and I really appreciate your contrarian perspective...
I love me a good game theory puzzle. There's a surprising amount of lore behind the game to "Guess 2/3 of the average" https://en.wikipedia.org/wiki/Guess_2/3_of_the_average