Seriously, take a moment, and think of a robot. But not just any robot—pick the robot that you think everyone else would choose if they were asked the same question. Before you read on, write it down, for the culture:
While we’re waiting for the webinar poll to finish (and to put some space between the test and the answer key), let’s take a brief, uh, timeout to talk about the NBA Finals.
It’s a sequence that happens in nearly playoff game. The home team goes on a run. There's a massive, career-defining block1 on one end of the court; the crowd goes wild. The block leads to a three on the other end; the crowd gets louder. On the next possession, a turnover, an outlet pass, a fast break, a booming dunk; pandemonium.
To stop the run, the coach of the away team takes three disgusted steps onto the court, snaps off a timeout, and wheels back to his huddle, glaring at his assistants. Mark Jackson hits us with a dumb catchphrase, and all of us watching on TV are unceremoniously dumped into a State Farm commercial.
As a fan on the couch, the timeout, which ejects me from a delirious arena into a cringy sales pitch for crypto, kills my excitement. But does it kill the home team's momentum? Are these timeouts, which coaches commonly take, actually useful?
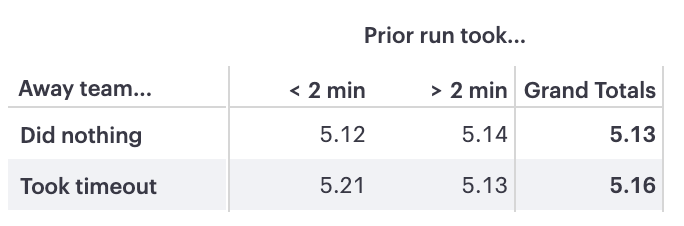
From 2015 to 2021, there were about 20,000 runs in the NBA, where a run is defined as the home team scoring at least eight of the last ten points in an uninterrupted stretch of play (e.g., no end-of-quarter breaks, no other timeouts, etc).
In 5,000 cases, the away team took a timeout, after which they scored an average of 5.16 points over the next ten points in the game. Though this seems positive—they broke the run!—most runs actually break themselves. In the 15,000 instances in which the away team didn’t take a timeout, they scored an average of 5.13 points over the next ten game points.
Moreover, timeouts have no effect at all if the run happens slowly. Of the 20,000 runs, about 12,000 took more than two minutes to develop. For those runs, the away team performed slightly better when they didn’t take a timeout. This is summarized in the table below, which shows the average number of points scored by the away team after a run by the home team.
Anyway, back to robots.
When I was asked to name a robot, my answer was WALL-E. If I had been asked to list a few more, I would’ve said HAL, R2-D2 and C-3PO, and whatever those things are that Boston Dynamics builds, which were clearly created by someone who was a little too obsessed with MechCommander as a teenager.
I'm told that these are pretty typical answers—for us olds.2 If you ask a youth the same question, nearly all of them will give the same appalling answer: Alexa.
As should be obvious to anyone with a modicum of sense, Alexa is not a robot. It does not have lightbulbs for eyes; it doesn't speak to us in foreign yet relatable beeps; it doesn't even have a real body. Alexa is no more of a robot than autocorrect, Google search, or my Spotify Discover playlist.3
But, if I’m more honest with myself than I care to be, these things could be robots. They don’t look like people, or do the things that we human beings do. But, to go full high school term paper for a sentence,4Webster defines robots as “devices that automatically perform complicated, often repetitive tasks.” That fits, if it must. Though I’ll never call Alexa a robot, I can at least concede that our lives are being taken over by the machines, even if they don’t look like the ones the movies of my childhood anticipated.
The same, I’m starting to think, will inevitably be true of the data industry.
Putting the artificial in artificial intelligence
I’ve long been skeptical of robots’ ability to perform the tasks of data professionals. Despite their hype, nearly all the tools that add automation to analysis—be it augmented analytics, AI-powered insight discovery, anomaly detection and alerting, or NLP querying—feel underwhelming. Augmented analytics tools, which market themselves as needle detectors for our giant haystacks of data, find mostly useless correlations, some spurious ones, and the occasional meaningful one. Alerts from anomaly detection services quickly become car alarms in a crowded parking lot: annoying false positives we learn to ignore, and wait for someone else to turn off. And NLP interfaces encourage us to ask questions about precise subjects in imprecise language, and hope that some black box built by three twenty-something YC founders with eighteen months of experience at Palantir trained a model that makes the same nuanced assumptions about what “weekly run rate by segment” means that I am.
Moreover, machine learning is often a structurally inappropriate solution for a lot of the problems that analysts want to solve. Your standard business question—for example, why are customer retention rates down, and what do we do about it—is deeply affected by lots of exogenous and qualitative factors. It relies on very few observations, like a couple dozen customers churning across a customer base in the hundreds. And, as both Randy Au and Sean Taylor called out in posts this week, decision makers don’t care about “technical” statistical significance; they want to see real, meaningful effects. To paraphrase Sean paraphrasing Garrett van Ryzin, when business leaders see an impact that matters, they don’t need statistics to know it.
In this light, today’s data robots aren’t much help. They’re oblivious to external forces; they confound themselves on small datasets; they can’t easily distinguish between statistical significance and colloquial significance.5 Even the academics are unimpressed: “The auto-insight tools we reviewed often provide relatively simple facts...Some visualization researchers feel that the auto-insights generated by existing tools do not align with the conceptualization of human insights being deep and complex.”
This is why analysts (should) get paid. They have to account for unaccountable factors. They have to draw concrete conclusions from uncertain trends. They have to know which statistically insignificant differences matter, and which statistically significant ones don’t. This requires an intuition and creativity that today’s robots don’t have. Boston Dynamics may be able to kill me, but they can’t replace me.
Or I used to think that. Now, I’m not so sure.
Putting the art in artificial intelligence
In dismissing the potential of AI in analytics, I’m falling into the same trap that I did with Alexa. I’m assuming that if we’re going to be conquered (or helped) by some robot army, it’ll look and act the same as I do—not physically, perhaps, but procedurally. It would alert me of the same concerns I worry about, answer the same questions I’m trying to answer, or produce the same output that I’m trying to produce. The problems it solves, in other words, would be familiar to me today.
Intellectually, it’s easy to see the flaw in this way of thinking—most big technological advances change problems as much as they solve them6—but it’s hard not to be constrained by it. To anticipate what something like AI might do to our lives, we have to look beyond the curve of the horizon, and imagine worlds we can’t yet see. As a technological cynic and general curmudgeon,7 I’m not cut out for that kind of thinking.
Fortunately, Sean Taylor is. In the same post as I mentioned earlier, Sean asked a provoking question: Could product managers use DALL-E 2, OpenAI’s rather remarkable image generating technology, to create dozens of new ideas for products to test? Could the tool’s seeming creativity serve as a substitute for our own? Is it possible that—ironically—giant, complicated regression machines are actually better at solving creative problems than they are at finding anomalous regressions?8
And could we do the same thing for analysis? In addition to producing an image or product proposal, an AI could generate reports and decks of business problems and metrics that attempt to explain them. While most of them might not make sense, there might be some revolutionary nuggets, like the “alien” chess strategies that emerged from Alpha Zero.9
The broader point is that this approach—use AI as a creative partner rather than a calculator for trudging through a bunch of repetitive math problems—is almost entirely different from how the industry has traditionally thought of applying it to analytics. This opens up a number of possibilities I’d never considered. To offer a few wild ideas:
An AI could ask questions rather than try to answer them. It reads the conversations people have about a business, and examines the charts that describe it. Then it asks dozens of questions, like a VC doing some kind of deranged diligence. Surely, a few of those questions would be, as Sean suggested, just weird enough to investigate.
An AI could offer suggestions for how to re-architect DAGs. If you use something like dbt for long enough, it eventually becomes a multi-generational ruin, where new cities get layered on top of old, until none of the streets quite line up. An AI could provide a series of redesigned maps, like an unpredictable urban planner suggesting optimal bus routes for connecting neighborhoods. Some may be ridiculous. Some might be good ideas.
An AI could parse SQL queries and semantic models, and attempt to explain them in plain English. Most AI-enabled tools go the other way, trying to turn loose descriptions of business problems into code. The opposite might be better: Turn code into accessible explanations of business concepts. Data teams are often asked questions—what exactly is a lead? How do we define weekly active users?—that are easily answerable if you could read SQL, Python, or LookML. An AI could do this for us—and if the explanation doesn’t make sense, people could just ask for another version.
Would any of these ideas actually be useful? Maybe. Are they even feasible to build? Doubtful. Will they come to pass? Almost certainly not—whatever I think the future will look like is surely wrong. The robots I can imagine today, and even the problems I can imagine them solving, probably aren’t the ones we’ll get. But, for better or for worse, I now believe it’s inevitable that we’ll get something.
Speaking of appalling, how many Taylor Swift covers do you think I to discover, Spotify? C’mon…as if I haven’t already listened to them on YouTube, the incognito window to my Spotify Wrapped.
In fairness to augmented analytics tools, I do think they can be useful if they’re applied to the right problems. While they aren’t suitable for figuring out why retention rates are down, they can be very useful when applied to large datasets where each record is a self-contained, independent(ish) trial. If you were to run a bunch of insight discovery algorithms over a highly dimensional table of every point-of-sale purchase at McDonald’s, you’d probably find something interesting. The bad news is that companies only have one or two datasets like that; the good news is that, if they do have them, they’re really valuable.
I think you are directionally correct. The thing we’ve seen at Nauto (and the centaur chess people already knew) is that *partnering* humans with AI is vastly more powerful than either alone: but designing the right partnership is the new hard problem!




I think you are directionally correct. The thing we’ve seen at Nauto (and the centaur chess people already knew) is that *partnering* humans with AI is vastly more powerful than either alone: but designing the right partnership is the new hard problem!