BI is dead
How an integration between Looker and Tableau fundamentally alters the data landscape.

It wasn’t the war that redrew Europe; it was the peace.
The Treaty of Versailles, signed in 1919 after more than four years of catastrophic conflict, created a new map of Europe. The agreement established nine new countries and thousands of miles of new borders, forever altering the political landscape of the continent.
Earlier this week, in a treaty of staggeringly less consequence, two of the data ecosystem’s biggest adversaries agreed to come together. Salesforce’s Tableau and Google’s Looker—major BI vendors, both of which were acquired four days apart in June of 2019—announced they’d soon be launching a technical integration between their two products.
The specific details are a bit vague, though the thrust of the partnership seems clear. Customers will be able to model data in LookML, and use Tableau, in addition to Looker’s native visualization tool, to explore that model. For people using Tableau’s side of the integration, Looker will, I believe, be invisible. Just as many of Tableau’s users are unaware of the Fivetran pipelines or dbt models that feed the data in their charts, they’ll likely be unaware of the Looker configurations that define the fields and metrics they’re exploring.
The market reaction to the announcement was a mix of surprise and indifference—surprise that two highly competitive companies would suddenly become friends, and indifference because two giants like Google and Salesforce are unlikely to get a complex integration like this one right. Moreover, even if the integration is technically sound, Tableau and Looker are both overlapping BI tools, and few companies use both at the same time. Companies choose Tableau or Looker, not Tableau and Looker.
I disagree on both fronts. Nothing about this is terribly surprising, other than Looker having the audacity to actually do it. And more importantly, the signals buried in this agreement have enormous implications for future of both BI and the broader data industry.
Looker = LookML = Governance ≠ BI
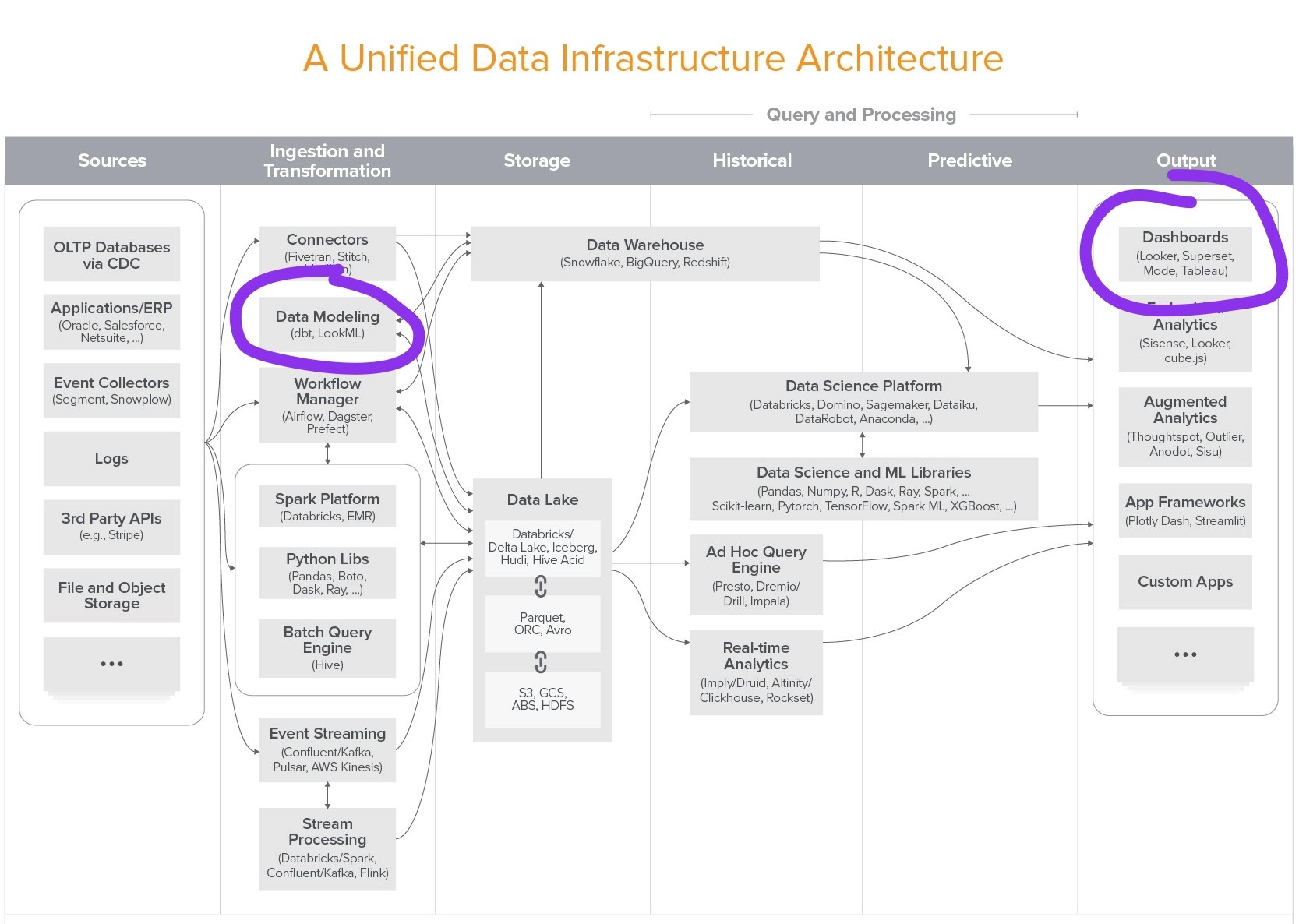
Looker, which combines a modeling layer with a visualization tool, has always been awkwardly arranged in today’s data architecture. The diagram below, from Andreessen Horowitz, illustrates the challenge of this pairing: Looker is split across multiple layers the stack.
{kind=link}
The industry’s horizontal pivot, which breaks data transformation and consumption into separate layers, makes this divide even more uncomfortable. As I said in the linked post, “tools that cut across these layers—including Looker, in my view—will eventually get pulled apart to align with the horizontal grooves the industry is carving.” This integration, which cleaves Looker’s modeling layer from its visualization tool, is exactly that.
Looker choosing to partner with Tableau makes particular sense because Looker’s always been a transformation tool first, and a consumption tool second. Looker’s crown jewel is LookML; Tableau’s is visualization. I’d speculate that Looker originally built its visualization tooling in large part so that they could market and sell the value of LookML, rather than the other way around. By launching this integration, Looker is simply doubling down on that long-standing identity.

When Looker got acquired, I thought Google would eventually acknowledge this. I said in an 2019 internal note about Google and Tableau acquisitions that, “over time, I expect LookML to be spun out of the BI application entirely, and offered as an independent, global governance solution within GCP. This could be the beginning of the bifurcation of traditional BI into two worlds: One for data governance and modeling applications, and one for the visualization and analytics applications.”
So far, the two layers have been peeled apart by products like dbt plucking elements of data governance out from under BI. This integration, though a continuation of that same trend, points to something bigger: Major BI tools are now also recognizing the combination of governance and consumption can’t hold.
The future of BI
To Google’s and Looker’s credit, it’s a bold bet. The market sees Looker as a BI tool, and this integration challenges that perception. Coincidentally, it directly raises a question that I asked in a recent post: “If you split Looker into LookML and a visualization tool, which one would be BI?” Or, in the terms of this integration, if you have both Looker and Tableau, which one is your BI tool?
My blunt answer is Tableau. You answer your questions in Tableau; BI tools are, above all, where questions get answered. Looker, in this realigned world, is squarely in the transformation layer—and specifically, part of the metrics layer. As I see it, this integration is the start of Looker’s retreat from fighting with visualization and exploration tools like Tableau, and an opening salvo in its campaign against metrics tools like Transform, Supergrain, Trace, and Metriql.
But even this understates the magnitude of the change. The partnership, if it presages a broader market pivot in the same direction, fundamentally redefines what BI is. In the same internal note from 2019, I speculated at that, “with the modeling layer removed, today’s BI applications—including Looker—become little more than pivot tables and dashboards. The applications that dominate this space will be defined by the richness of their analytics applications and how efficiently they facilitate collaborations among and between all levels of data users.”
In other words, BI as we know it is dead. BI as global exploration is ascendent.1
Is the economy stupid?
As an analyst, I want to use the products created by this realigned world. It’s less clear, however, that I want to buy them.
A number of folks have already raised this concern. Tableau and Looker are both expensive BI tools. How do you justify buying both?
On one hand, easily—they do different things. Looker governs data; Tableau helps people explore it. The rationale for buying Tableau and Looker is no different than that for buying Tableau and Transform, or even Tableau and dbt.2
On the other hand, this hints at a bigger question about buying data tools. The list of what we need in a modern data stack—logging infrastructure, inbound ETL, a warehouse, a modeling layer, a metrics layer, an advanced analytics tool, a code-free exploration tool, a catalog, reserve ETL, an observability tool—is getting long. While most new tools are technically easy to deploy, they’re not always easy to buy, nor are they collectively affordable. In addition to a modern data experience for users, we need a modern data experience for buyers.
I don’t know how this problem gets resolved. It’s possible that tools build white-label integrations with one another so that you only have to buy from a few vendors. It’s possible that most products are absorbed by behemoths like Google and Salesforce. It’s possible that independent vendors merge into companies like Atlassian that operate as a federation of independent applications. It’s possible that a market pops up for companies and services that manage all of this for you. It’s possible that we don’t figure it out, and we live with the headache. And it’s possible that it just never becomes that much of a problem.
That said, the Looker and Tableau integration provides at least one interesting signal. My belief has long been that consolidation under Google, Amazon, Microsoft, and Salesforce is the most likely outcome. These companies, sitting on nearly $400 billion in cash, aren’t going to sit on the sidelines of, according to Andreessen Horowitz’s Martin Casado, a trillion dollar data market. They’ve already built enormous businesses on top of collections of cloud computing services; it seems natural for them to do the same on data services.
Over the last couple years, Google (and specifically GCP) has been apparently moving in this direction. Google built BigQuery for data storage, Data Studio for visualization, and Colab for advanced analytics; they acquired Alooma for ETL, Dataform for transformation, and Looker for governance and metric calculation. All the pieces for the Google Modern Data Experience™ are there, provided that they can make them all work together.
But this integration implies an interesting admission from Google: They don’t believe in their own data exploration tools just yet. In 2019, though I thought Google would strip LookML out of Looker, I assumed Google Data Studio would be the first integration. By choosing Tableau, Google’s conceding, at least for the time being, that their data stack ends with LookML’s metrics layer.
This gives GCP some optionality. Because everything below the metrics layer is still, at least loosely, infrastructure, Google’s data services could just be another subheader in the GCP catalog. Their offerings are still services oriented around compute rather than seats, sold to IT teams, engineers, and devops teams and their analytical equivalents. In this world, the cloud service providers become the major combatants in the market for data infrastructure, while data consumption products designed for end-users and sold on a per-seat basis—including exploration tools, a reconstituted BI, and data apps—are built by the rest of the ecosystem.
Alternatively, Google could simply be regrouping. They, and their other trillion-dollar rivals, may see the entire data landscape as their next theater. Rather than a lasting peace, this integration could be a momentary pause, setting the stage for a fight over the next big data market: data applications and experiences.
Admittedly, I have a horse in this race. At the end of the same internal note, when talking about the breakup of transformation and exploration, I said, “that’s the world that Mode is focused on serving.” At Mode, we haven’t built traditional data modeling features—which is unusual for something that looks like a BI tool—because we believe in this pivot.
I am interested, however, in how this realignment affects Looker’s pricing model. Looker charges its customers based on several factors, including seats. If customers use Tableau for data exploration, it’s not clear what Looker will charge for. (This is part of the reason I disagree with the reactions that the integration doesn’t make sense because it’ll cost so much. That assumes Looker doesn’t change its pricing model.) Looker likely can’t charge for seats, because far fewer people will need seats than they need today. And they can’t charge for compute, because Looker relies on the database to handle most of it. That may point to the plan, though: Google wants to use this integration to put LookML underneath a bunch of Tableau customers, with the hopes of selling them BigQuery later.
Really great analysis. I've been thinking much the same for a while now and also chewing on how, as we get better at understanding what it takes to create that utopian, unified data platform, and the lengthy list of tools and capability it's gonna need. How do we encourage better behaviours and architectures when everything is so damn expensive? We have an industry with a rich history of gouging its customers and making every little thing ultra expensive. I can only hope that we see what happened in the software world over a decade ago, and see a surge of free open source tooling driven by engineers fed up with doing everything so badly. Given the influx of software engineers into the data field, I am crossing my fingers.. As Dave points out in his comment, there is value in decoupling a semantic layer for data from visualisations and dashboards... It also goes far beyond just that.
Hi Ben, I’d like to have you join us on Data Sharks. Let me know if you’re interested. https://youtube.com/playlist?list=PLIBwmCV8YuLPOKsqwovvBgMhBDwYYyB85