Copy copy revolution
Embracing the radical simplicity of an absent-minded architect. Plus, a tight race at the top of the White Lotus Power Rankings.

In a recent post about how AI is writing more and more code, Tristan from dbt Labs imagines a nightmare:
Claude 3.7 will write you almost any kind of code you could want. You can absolutely build a pipeline from the ground up, building ingestion, transformation, testing, etc. in Lisp. In Assembly. In the style of Guido van Rossum. Whatever. You could even imagine a world in which you had 1,000 distinct pipelines and every one was written in a different language or framework or set of conventions. All reading from and writing to a shared corpus of tabular data.
But: just because it is now conceivable to create such a codebase, is it a good idea?
The answer is: no. Obviously not. Just as a team of humans would have an impossible task of maintaining such a Frankenstein, the heterogeneity would make it intractable for LLMs as well.
These days, this isn’t a particularly controversial point. Yes, large language models can write code; yes, they can build impressive things in extraordinarily short amounts of time; yes, it is tempting to chuck a few prompts at Claude or Cursor and call yourself an engineer.
But, we are warned, this is ignorant. AI agents are a fool’s idea of an engineer, and when you don't know what a profession does, you trivialize it. Though what these bots bots build works well at first, they can’t anticipate how a piece of software might evolve. They blithely write code to satisfy the demand of the moment, without leaving space for what might come next. They build a product the way a toddler builds a tower—one haphazard block at a time, until it collapses. According to one experienced programmer, the bots can type, but only an engineer can think:
If I ask the AI to generate 80% of my code without my experienced programmer handholding on every line/few lines, it’s more likely than not hot garbage that takes me longer to fix than writing from scratch. I’ve also generated entire small projects that appear to work, but the underlying code is so poor it’s gonna implode if you keep iterating and adding complexity.
If you’ve built anything with a tool like Cursor, you quickly begin to have the same reaction: It writes an explosively large codebase. When you ask it to add a new feature, it builds it from the ground up, writing hundreds of new lines of code while only deleting a handful. It constantly repeats itself. It is as though it’s an absent-minded architect who adds a new elevator for every floor in a skyscraper, because it forgot that there are already thirty elevators in the lobby.
The Experienced Programmer would not do this. They would build with components—create a function in one place, and reuse it everywhere; maintain single sources of logical truth; build a shared elevator for the entire building. There is a balance here, of course; sometimes, a bit of light repetition is more useful than a fancy abstraction that is hard to understand. But that is the reasoning that an engineer is paid to do—to think about what will make the intricate operations of a software product easy to build and maintain.
In other words, AI writes code that is bad. Engineers (can) write code that is good.
But, there is a lot of nuance here, in what it means to be good. And ten years ago, Rich Hickey, who is such an Experienced Programmer that he has a Wikipedia page, gave a famous talk about one such nuance—the difference between code that is simple and code that is easy:
Simple things are uncomplicated. They have very few layers and folds; they do not have many moving parts. A line is simple; a knot is complex. A two-string erhu is simple; a 41-key accordion is complex. A sword is simple; a drone equipped with eight Hellfire missiles and high-powered cameras is complex. And critically, simple is “an objective thing. You can go and look and see. I do not see any connections. I do not see anywhere where this twists with something else.”
Easy, by contrast, is relative. Easy describes something’s proximity to someone’s abilities, so you can't define easy without knowing who it is easy for. Both the erhu and the accordion are hard for me, and both are easy for professional musicians. A sword is hard for George Michael but easy for Darth Maul, while a drone with eight hellfire missiles and high-powered cameras is easy for Staff Sergeant Jeremiah Walker.
According to Hickey, we often confuse the two ideas. Because frameworks and abstractions are shortcuts that engineers are used to using, they are, to the experienced programmer, familiar. They are easy.
But they aren’t simple. An abstraction is a layer cake of logic; a component that is reused across an application is a lever with many strings attached to it. These are complex things with many moving parts, and eventually, Hickey says, this complexity will overwhelm all of us:1
How many things can you keep in mind at a time? It is a limited number, and it is a very small number. So we can only consider a few things and, when things are intertwined together, we lose the ability to take them in isolation.
So if every time I think I pull out a new part of the software I need to comprehend, and it is attached to another thing, I have to pull that other thing into my mind because I cannot think about the one without the other. That is the nature of them being intertwined. So every intertwining is adding this burden, and the burden is kind of combinatorial as to the number of things that we can consider. So, fundamentally, this complexity, and by complexity I mean this braiding together of things, is going to limit our ability to understand our systems.
This is the fate of nearly every major engineering project; this is the seemingly inevitable entropy of modern software engineering. The feature set expands; logic slowly gets intertwined; the strings between different components and classes get twisted and tied together. Updates that happen on one side of an application start to cause unanticipated vibrations on the other side of it. Development slows down. Every sprint accomplishes less. People spend all their time redoing things that have already been done. Bugs become more common and harder to fix, until you accidentally pre-populate the “amount” field of a wire transfer form with 15 zeros, someone doesn’t notice, they try to send a customer $280 but send them $81 trillion instead, which is about $80 trillion more than the amount of money you have, oops, and now you are broke and fired and maybe going to jail. That is the cost of complexity—90 percent of all the money in the world.
The only way to avoid this eventual fate, Hickey says, is to keep things as simple as we can for as long as we can. But there are limits to this too. Because, while abstractions and components and frameworks add complexity—two buttons calling the same function is a form of logical intertwining, for example—we can’t reason about a million simple things either. We can’t update a million functions that do the same thing, or maintain a different stylesheet for popup. It would be simpler to do this—for every function to do exactly one thing; for every element to have its own styles; for every floor to have its own elevator—but we would get overwhelmed again, by the volume of it all:
The juggling analogy is pretty close [to software engineering]. The average juggler can do three balls. The most amazing juggler in the world can do 9 balls or 12 or something like that. They cannot do 20 or 100. We are all very limited.2
Ultimately, that is the art of the entire endeavor. It is finding the right balance. It is figuring out the right number of elevators to build. It is keeping things simple enough for us to understand them, while using just enough abstraction to save us from having to remember everything—because, we are only human, and we can only keep so much in our head at once.
You can see where this is going.
To borrow Hickey’s language, complexity and volume are both hard for people; neither is near to our abilities. For computers, only complexity is hard. Volume is trivial. Volume is what computers do. Volume isn’t just near to their abilities; it’s their whole thing.
AI agents may or may not be smarter than us, and they may or may not be able to reason about more complex things than we can. But they can unquestionably reason about a larger number of things. They are unquestionably more diligent and more relentless. They are unquestionably better at inhaling millions of words of text and lines of code, and plowing through thousands of repetitive tasks. They are unquestionably better at juggling more balls than we are, and remembering where they put all of the elevators.
Which means they can build more of them. They don’t need to abstract and reuse code—which adds complexity—because they can just duplicate and remember it. They don’t need to use frameworks to save themselves from their frail memories and feeble muscles. A dedicated function for every button? A CSS class for every element?3 A straight line between every artifact and what the application needs it to do? That’s a very simple codebase—too simple, in fact, because it is far too large for us to keep in our heads. But is it too large for their heads and inexhaustible hands?4
—
When you use an AI coding tool, you find yourself constantly fighting against its verbose tendencies. “Can you consolidate this into something simpler? Can you look for places where there’s duplicated logic and clean that up? Can you try this change again, but without adding so many new lines of code?” It’s tempting to do this because I’m reading the code it writes, I want that code to make sense to me and to be proximate to my abilities, and when it is not, it is bad code that needs to be fixed.
But is that right? Or is that just me refusing to learn another variation of the same bitter lesson that we’ve been taught over and over again—that computers are at their best when they’re unencumbered by the aesthetic preferences of the human mind? Is fighting Cursor’s enthusiasm for duplication another doomed battle in the war that we’ve been losing for decades?
Researchers always tried to make systems that worked the way the researchers thought their own minds worked—they tried to put that knowledge in their systems—but it proved ultimately counterproductive, and a colossal waste of researcher's time, when, through Moore's law, massive computation became available and a means was found to put it to good use.
…
We have to learn the bitter lesson that building in how we think we think does not work in the long run. The bitter lesson is based on the historical observations that 1) AI researchers have often tried to build knowledge into their agents, 2) this always helps in the short term, and is personally satisfying to the researcher, but 3) in the long run it plateaus and even inhibits further progress, and 4) breakthrough progress eventually arrives by an opposing approach based on scaling computation by search and learning. The eventual success is tinged with bitterness, and often incompletely digested, because it is success over a favored, human-centric approach.
Perhaps we should let the machine write for itself and its abilities. Let it be redudant. Let it ignore the frameworks; let it create explosively large codebases. Let it write 1,000 distinct pipelines in 1,000 distinct languages. Let it be offensively unaesthetic. Let it be radically simple.
I doubt that an untethered AI agent would work exactly this way, or even be particularly close, at least without a different form of handholding. We may have to instruct them to write like this, especially because they’re trained on man-made codebases that prefer some abstraction to absolute simplicity.
But that could be the irony of AI coding agents: If we can stretch them away from their training data and coax them into writing code that is further from our abilities, they might actually get closer to our ideals.
The White Lotus Power Rankings
It’s been a real good week for Sritala:
WARNING: Light episode four spoilers.
After episode three, Sritala was voted “most likely to be dead.” After episode four—the episode that aired 12 days ago—she plummeted to ninth. (Her husband, I suspect, would not have fared as well.)
Other people on the move: Belinda is rising up the sus ranks—which, yeah, makes sense—but a now-paranoid Greg is falling? And Tim, the spiraling drug-addled desperado who literally just stole a gun, is also falling?
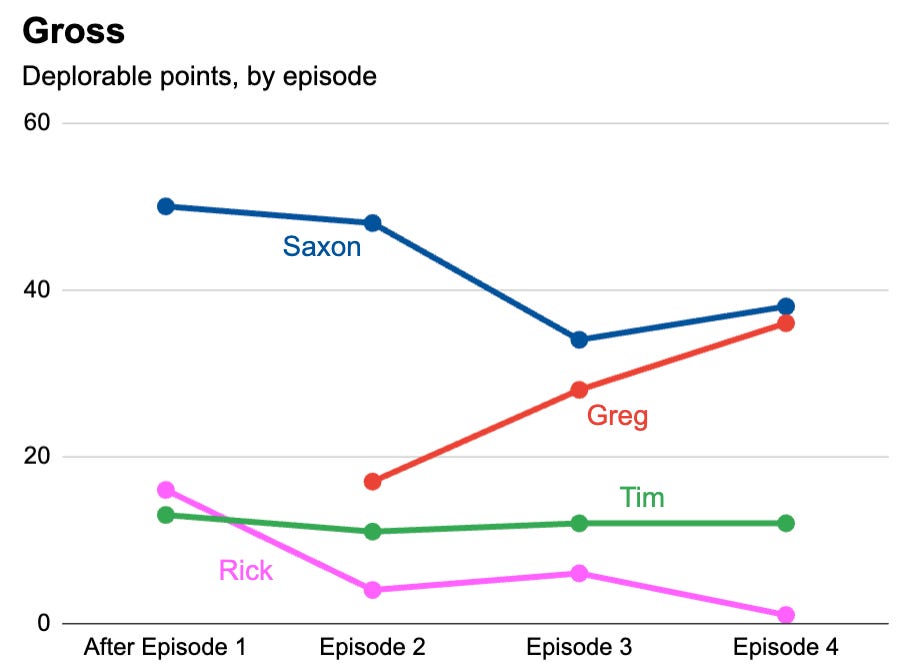
Plus, the race for most deplorable is tightening up:
Anyway, vote for episode five (the one that aired five days ago)! By popular demand—and because one of them should be the clear winner in one of the categories—new characters have been added! (But no, not that character.)
Also, lots of you have asked for the data. Here are the anonymized results. If you find something fun, I’ll share it (and, like, your Soundcloud or whatever) here. And if you need a tool to analyze things, I mean, you know.
A transcript, if you prefer.
Though Hickey uses this specific analogy to talk about how many folds we can understand in a complex thing, I’d argue that this isn’t really a distinct point. A complex thing is just a bunch of interwoven simple things. If we can’t juggle a complex thing because it requires us to juggle too many simple things, we can’t juggle a bunch of independent simple things either.
Tailwind, a CSS framework, basically does this, and is very popular because of it. Typically, CSS classes are defined by element: There are classes like .button and .error-message, and font sizes, colors, and borders are defined within each class. Tailwind uses utility classes like .text-white for white text, and .m4 for adding 4 pixel margins. These classes are then added directly to every element. It’s a lot of duplication, because every button will have a list of classes assigned to it. But because each style is explicitly defined directly on the button itself, it’s much simpler than more traditional approaches.
Anyway, the whole point of this post is basically to ask, “could we do this for other things too?”
I mean, it might be, if we define their heads as the context window of an LLM. But that window will surely get bigger, and more importantly, that’s too crude of a definition of an LLM’s head. In any case, it doesn’t seem at all controversial to say that, compared to a person, an AI engineer has a far greater capacity to reliably update a simple but expansive codebase.
+1 for Krazam
Our brains aren’t very good at comprehending how much knowledge that can fit into a 200k token context window. In terms of football fields and 747s, each question to an LLM can contain nearly 2 complete Lord of the Rings.
https://open.substack.com/pub/drewbeaupre/p/give-the-ai-the-full-picture
So what if we embrace this? What changes if we can 10x the context size?