Fine, let's talk about data contracts
I agree that disagreement is a problem, but disagree that we need an agreement to solve it.

The walls have been closing in for a while now.
Data contracts first entered the conversation at a safe distance: On LinkedIn.1 But recently, they’ve started inching closer to home. The idea jumped the usual firewall between LinkedIn and Twitter, made its way onto Substack, into the replies, and eventually, in the ultimate temptation, into fights.
Gah. Fine. Let’s get this over with.
My initial reaction to data contracts was the same as my reaction to the data mesh. Both struck me as a kind of Rorschach proposition: Something defined well enough that we can all sense its shape, but abstract enough that we can also project our own opinions on top of it. Shapeshifting ideas like these are magnets for debate—it’s easy to say what you think a cloud looks like—but impossible to pin down. The moment we agree on what one corner of it should be, the rest of it melts into something new.
To my profound disappointment, I think I was wrong. There is something useful here that’s worth talking about, and some concrete architectural points to discuss.2 I don’t think it looks like the data contracts that have been proposed in other places—and it may not be a proper contract at all—but, before we all move on to the next new thing, I have some ideas about where to put the bike shed.
No liquids, aerosols, or gels
Over the last few years, the data ecosystem has blown up. This hasn’t just attracted new tools and vendors, though it’s certainly done that; it’s also created a lot of new data producers and consumers within businesses. Companies source data from production applications, from event streams, and from third-party SaaS applications like Salesforce and Hubspot. That data is stuffed into a warehouse, passes through some transformation pipelines, pays the Snowflake toll a few times, and eventually finds its way to a dashboard, into a customer-facing product or an internal application, or back into third-party SaaS services.3
Useful as this may be—and critical as it is for many businesses’ operations—the entire system is pretty flimsy. It’s all interconnected, and the connections are unspecified. Transformation pipelines usually assume data will continue to arrive in the warehouse as it did when the pipe was built; dashboards usually assume data will continue to be transformed in the way it was when they were created. On every edge between every node, there’s an implicit, unrecorded expectation on both sides. This means we often have no idea what’s going to happen when we change something. It might be fine, or it might break everything—and if it does, we’ll catch it in production.4
Data contracts are a proposal for solving this problem. As best I can tell, they have two core components. First, the people on the two sides of the connection—the engineer building the application that feeds data into the warehouse, and the analytics engineer building a pipeline on top of it, say—get together to figure out what that connection should look like. The engineer negotiates on what they can reasonably provide; the analytics engineer negotiates on what they need. At some point—after either a short conversation or a long series of calls, decks, proposals, counter proposals, and amendments that eventually coalesce into a deal—they agree on something.
Once they do, those expectations are codified. The exact mechanism for this seems to vary, though most arrangements involve sticking some service in between the data source and the database that checks if incoming data meets the agreed-upon standard. Data contracts are the database’s TSA: They screen new arrivals to make sure they don't have any bombs, bazookas, or 3.5 ounce tubes of toothpaste.5
No doubt, the problem data contracts aim to solve—keep the lead out of the water, before it gets to people’s faucets—is a real one, and well worth solving. Just last week, we updated how we record customer contracts in Salesforce, our downstream reporting broke, and less than a day after making the initial change, a customer success manager presented incorrect information to a customer. This is what finding errors in production looks like—and it can get much worse.
Data contracts also have ancillary benefits. They offer a clear way to define what’s in production. They also provide a means for describing the output of what data tools are supposed to produce. Today, most pipelines are procedural tasks: Write from this source to this destination; execute this code; hope what comes out the other end looks like what we thought it would. A data contract adds an expectation to these jobs by specifying what the result should look like. This not only makes the system more durable, but it also makes declarative DAGs possible.6
However, the way data contracts try to achieve this though—through a negotiated agreement—seems wrong on all fronts: It’s impractical to achieve, impossible to maintain, and—most damning of all—an undesirable outcome to chase.
You can’t stop Salesforce, you can only hope to contain it
A smart person once told me that the most foolish thing you could do is turn a technology problem into a people problem. For all their faults, they said, computers aren’t fickle or unpredictable. No matter how painful it is to reconcile mismatched code in a computer or messy data in a database, neither are nearly as hard as getting ten people to agree on anything.7
Data contracts make exactly that trade. They replace a brittle technical system with a negotiating table. And the more that contracts depend on one another, the more people will want to be involved. I don’t know if that kills innovation, but it’s at least an annoying set of conversations that most people don’t want to have.
Moreover, even if we do create these contracts, a lot of data “providers” (e.g., software engineers who are maintaining an application database, and sales ops managers who configure Salesforce) can’t guarantee them anyway. If you change some bit of logic in Salesforce—if, for example, a team stops recording pricing information on the product object and starts recording it on the product attribute object—it’s hard to know how that change will be reflected in the underlying data model. Salesforce’s UI exists for exactly that reason—so that we don’t have to think about our entire CRM as a bunch of tables and an entity-relationship diagram. If administrators sign a contract to maintain a particular data structure, how can we expect them to hit what they can’t see?
Finally, I’d also argue that we don’t want data providers to be worried about these contracts in the first place. Engineers, marketers, sales operations managers—all of these people have more important jobs to do than providing consistent data to a data team. They need to build great products, find new customers, and help sales teams sell that product to those customers. The data structures they create are in service of these goals. If those structures need to change to make a product better or to smooth over a kink in the sales cycle, they shouldn’t have to consult an analytics engineer first. In other words, data teams can’t expect to stop changes to products or Salesforce; we can only hope to contain them. Though there may be exceptions, most notably when data circles its way back to customer-facing production systems, data teams are the tail.8 We should be told when something changes, but it’s a notification, not a negotiation.
But, some people might say, we can’t do our job without quality data. We can’t serve good food if we get bad food from the kitchen. True—but this subtly shifts the goal posts. If data contracts are meant to prevent us from serving bad food, we can do that on our own. Before we start demanding higher quality data from our providers—and passing the responsibility of what we deliver off to them—we should prove that we know how to identify low quality data first.
To put it another way, data contracts shouldn’t introduce unnecessary and impractical negotiations to extract promises from data providers that they can’t and shouldn’t keep. They should instead be a simple defense—built by data teams, for data teams—against communication failures. They should be a technical solution that protect against human mistakes, not organizational red tape layered on top of a technological mess.
The data contract I want
The good news is these safeguards are something that we can build today, in our existing infrastructure.
Today, most architectures look like the diagram below. Data gets written into a warehouse in its raw form; it’s transformed by dbt; and then goes on its merry way to whatever output is next—a dashboard, an operational tool, an application, whatever. Data quality checks, like dbt tests and observability tools, run after the fact, in production.
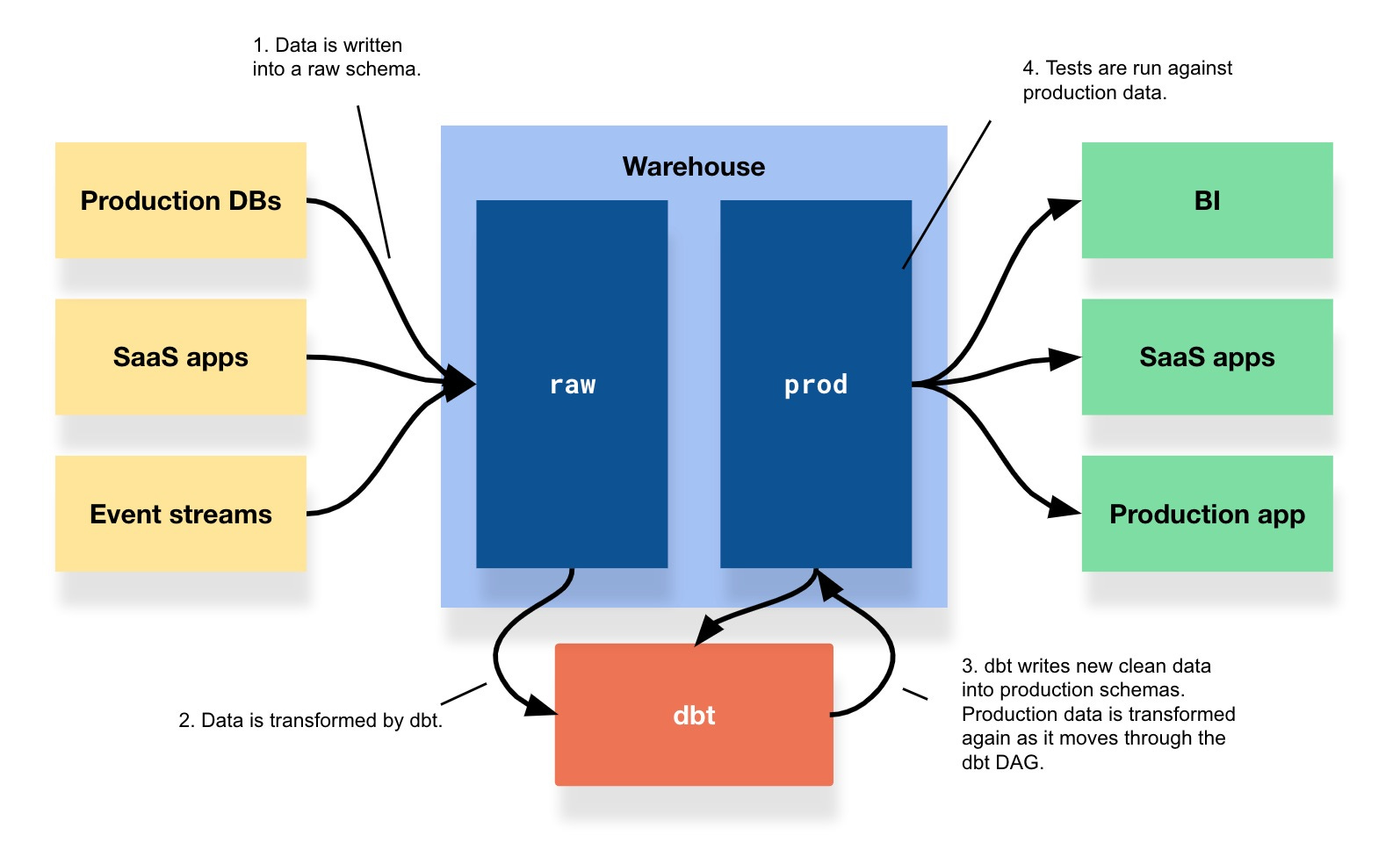
Most proposals for data contracts stick some testing mechanism—the TSA screening—on the database’s front door. This is better than nothing, but there’s a simpler way to solve the same problem with a tools we already have: database schemas.9
Anything that writes to the database writes to a staging schema.10 We define data contracts—or, dbt tests, as is often already done—against those tables. When the table updates, the test runs. If it passes, the table moves to the destination schema that we write to today. If the test fails, someone gets an alert, and the data stays put—and therefore, never reaches production. And if we don’t care about testing against the table, we don’t specify a contract and the table passes through the staging schema instantly.
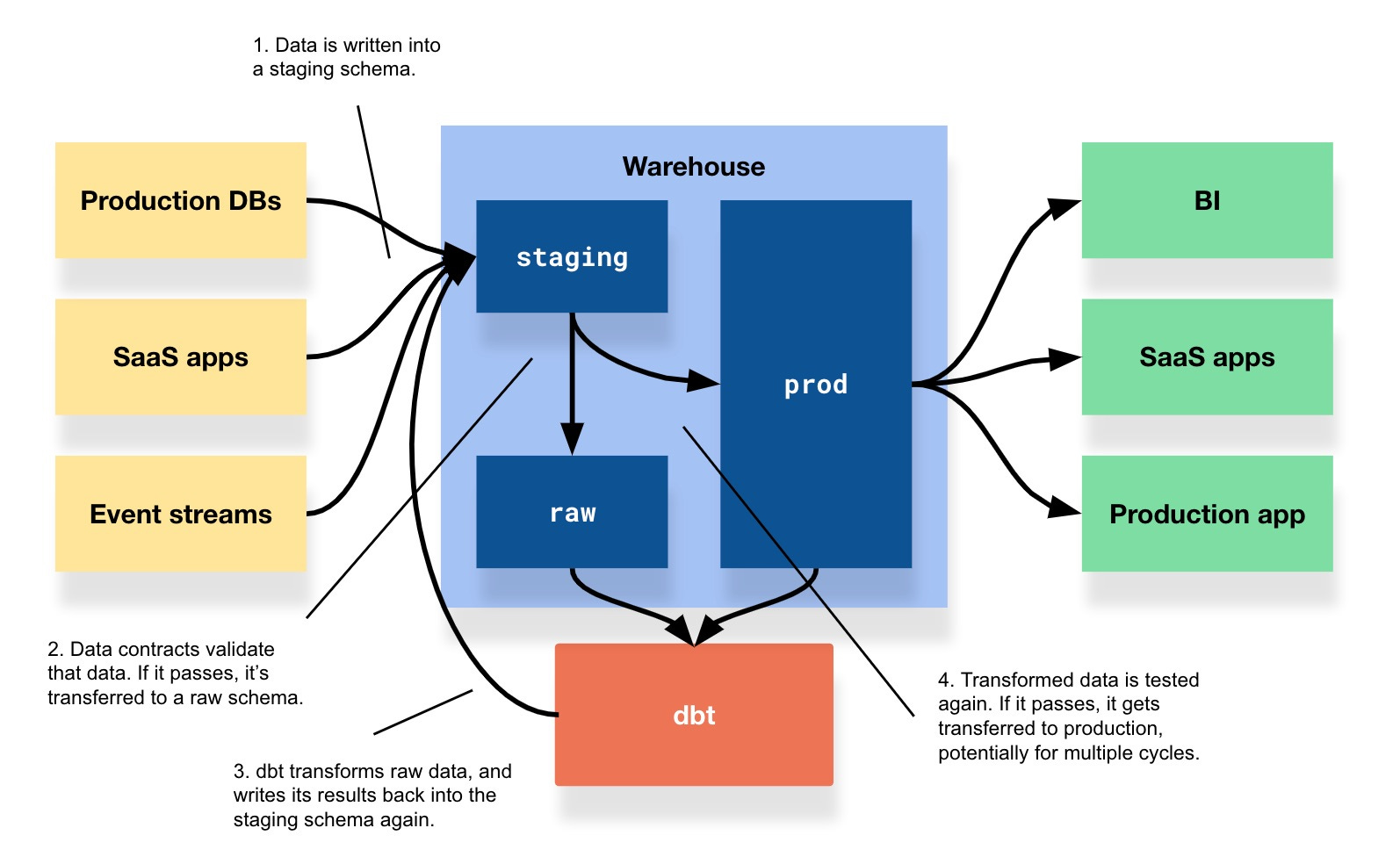
This structure satisfies our primary problem: It tests data before it reaches production, not after. By writing to a staging table, debugging a violated contract is also easy, since you can directly inspect the table that caused the failure.
Second, unlike in the TSA approach, tests like these can be applied across all stages of transformation, not just when data is written into the warehouse. Every dbt job could write to staging as well, and every model could be checked against their respective contracts (this detail is how this differs from standard dbt tests, I believe). This provides governance over intermediate steps, and visibility into exactly which step caused a violation.
And finally, this framework fits neatly into today’s most common architectures. I’d imagine you could rejigger most dbt projects to operate exactly this way, and a few clever dbt macros could probably handle the renaming gymnastics. This would also be an ideal candidate for Snowflake’s app store: Build a simple interface for defining contracts (i.e., tests) against tables, and have the app run those tests whenever tables get updated.
Both versions could be extended further, and offer a dedicated web interface for viewing all of the tests. This has a benefit beyond simple convenience: It helps other people, notably data providers, see what expectations are in place. Though they have no obligation to meet those guarantees, I suspect most people would try to respect them, if they know what they are.
Obviously, this arrangement isn’t not perfect. Running a bunch of tests in the warehouse incurs more costs. It might introduce additional latency. I’m sure it creates all sorts of problems for tables that are loading incrementally.11
But if I handwave past these things—I’m a pundit now, not a practitioner—it checks all the major boxes. It protects data teams from pushing bad data into production; it provides a means for defining what is production; it offers a self-contained way to encode expectations into data pipelines; it helps teams inspect the data that violate those expectations. And somebody’s probably already built it, and shared it in some Discourse channel years ago.12
My suspicion is that most existing data contracts, to the extent that these things exist in the wild, look more like this rather than agreements that were hammered out between grizzled negotiators. I’d bet that they’re tests that got introduced after the fact—the data looks this way today, and, with this new test, we’re formally declaring that we expect it to keep looking that way tomorrow.
Admittedly, that doesn’t sound as novel as a data contract, and “staging schemas” don’t make for much of a LinkedIn conversation. But that’s why I stay on Twitter—nobody expects you to come up with revolutionary ideas in 280 characters.
It’s funny the degree to which the online data world is split in half between Twitter and LinkedIn. Outside of a few brave ambassadors, there seems to be very little overlap. Both networks have their influencers and reply guys, but the regulars on one are rarely the regulars on the other. (The true pioneers could move to TikTok, but then they’d have to compete with Miss Excel.)
Sorry, TJ. In my defense, I tried to ship stuff at Mode, but can’t hold down a job doing it. And like most failed practitioners, I have nowhere left to go but to become an out-of-touch talking head that debates what other people are going to do.
Is saying SaaS service like saying ATM machine? Or is SaaS an adjective, and software-as-a-service service is allowed?
This song (and, amazingly, the artist) sums up most companies’ strategy for maintaining high quality data.
All these four ounce tubes are a conspiracy between the feds and Sensodyne to make us buy more toothpaste and to get TSA agents free confiscated toothpaste, and you can’t convince me otherwise.
In that original post, I said that the only difference between our internal transformation tools and dbt was the scheduler. There was actually a second difference: Our internal tools required people to define the schema of every model, as in this example. This was, in effect, a very dumb yet very effective data contract that I’d love for dbt to adopt. If schemas or data types changed, the job would fail.
I'm no techno-apologist, but if we’re going to save ourselves from climate change, I’m more optimistic about some Thiel Fellow inventing cold fusion in a MAGA-fueled effort to own the libs than I am about Joe Manchin and Kyrsten Sinema negotiating their way to meaningful political solution.
To be more blunt about it, why should we expect other teams to agree to these contracts at all? Would we do it ourselves? Suppose that the finance team comes to us and says we need to organize our data infrastructure in a very particular way because it helps with invoicing. They can still do their job if we change it, but it’ll cause an inconvenience. I suspect most of us would do our best to be helpful—we don’t need to go full Microsoft on everyone—but we wouldn’t promise to consult with them every time we wanted to add a new schema to our warehouse.
Schemas, it’s always schemas.
I’m using staging to mean something slightly more expansive than how dbt typically uses it.
Something something Materialize.
In a way, this is describing a dumbed-down version of Dagster as well. Dagster does more than this, but you could probably repurpose it for exactly this problem. (I’m a very small investor in Dagster.)
So are data contracts basically what we'd have handled in "the old days" with CHECK constraints and RI on the destination table? Define what is logically acceptable in the DDL and let the RDBMS keep bad data out at load time, and make sure that the tool loading the data from raw understands how to handle constraint violations?
Two thoughts.
First, there is a category of issues around source data that cannot be detected nor verified with automated testing. It can't be known by the recipient of the data unless the provider of the data informs them of it. And this is related to a category of statements around data contracts that by definition must be at the business meaning level and not the technical level.
Let me give an example of an inter-company interface that we've built recently which relates to the business-meaning level of data contracts.
We have a client for whom we have built an analytics platform which has, among its data sources, payroll information. The payroll information we receive has to do with employees working on contracts (I know, employees working on contracts seem strange, but bear with me, it's an unusual kind of payroll situation, and I can't give more business detail without providing inappropriate information.)
So, the incoming data looks a bit like this:
EMPLOYEE_ID | CONTRACT_ID | BUNCH_OF_OTHER_FIELDS
It is provided in our Snowflake environment via a Snowflake data share (private) and the vendor does a batch recalculation of the payroll data every night.
The payroll data is supposed to provide one record every time an employee starts on a new contract. So the grain is one row per EMPLOYEE_ID per CONTRACT_ID. The business meaning of this is that an employee can be working on multiple different contracts. Any new contract is supposed to be defined by a new combination of EMPLOYEE_ID and CONTRACT_ID. There can be updates to the various other fields associated with a contract such as the contract start date, end date, payment rate, location, etc. When a contract is updated, theoretically, the fields associated with the same EMPLOYEE_ID and CONTRACT_ID should just be updated.
Also, the payroll vendor does have a fairly normalized schema upstream of a number of different tables which are the back-end of their payroll processing system, but they will not provide that for various legal reasons (which don't make sense, and we've tried to get it, but they refuse.) They only provide this one denormalized table.
Well, we recently found out that sometimes the data entry team at the payroll vendor, instead of editing existing contract data, sometimes just creates a new record - same EMPLOYEE_ID but new CONTRACT_ID. And we also continue to get the old record. Records don't age out of the feed until a couple of years after the contract date. What makes this even more challenging is that it is very possible, and fairly common, for an employee to legitimately be working on two or more different contracts. We can't reliably tell the difference between what is actually a true, new contract, versus what is actually a change to an existing contract. Yes, we could try to get into all sorts of fancy comparisons on other fields, but that is error-prone and unreliable, and any rules we create around that could also break as the habits of upstream data entry folks change. We also don't get actual database insert or update timestamps on the data, and because it is denormalized down from quite a number of source tables in a way that is not transparent to us, it wouldn't really help anyway.
Thus, there's no reliable way for us to write a rule to detect when the upstream payroll vendor is erroneously entering contract changes as new contracts instead of editing existing contracts as they should. Technically, everything is correct - there are no duplicates when looking at the compound primary key of EMPLOYEE_ID and CONTRACT_ID. But - the business rule, the spirit of the thing, is being violated. I don't see a way to automate this or even detect it on our end except for actually getting the data provider to agree to the spirit of the data contract, and to put effort into working with their data entry team, and also monitoring what they are entering on an ongoing basis to make sure that it is correct.
Second thought.
I also think that discussing how data contracts work WITHIN an organization - where there can be better informal agreements and negotiation - is a very different conversation regarding how data contracts can/need to/must work BETWEEN entirely different organizations. You can do a lot more legwork and relationship building where, when being within a given organization, team members at least theoretically share some sense of mission, allegiance, or goal. When going entirely outside of your organization and to an entirely different organization, and needing to build an ingest or feed with a whole different firm that likely has an entirely different set of incentives, timelines, goals, and personnel, it gets a lot tougher. My thoughts here on building data interfaces between organizations here, which are, unfortunately, a lot more formal and perhaps even litigious, than yours: https://jrandrews.net/risks-of-interfaces-with-partners/
TL;DR - IMHO between organizations you really need to have an actual *legal* contract, with the technical folks involved in the negotiations and not just the attorneys, and there needs to be actual specific financial penalties for each enumerated breach of contract, to really push large organizations to work together.