The unspoken gerrymandering of the modern data stack
Carving up tools with a no-code cleaver.
We were somewhere around June on the edge of our third month in deep quarantine when the cabin fever began to take hold.
I hadn’t traveled more than three blocks in weeks. The only live sports on TV were the national cornhole championships. I was drinking more margaritas than a Jimmy Buffet groupie.
Lost in this fog, somewhere between working from a coffee table and wasting away in Margaritaville, I found myself tumbling down a very particular YouTube rabbit hole: Videos of college professors giving their first lecture of a new semester. With students still shuffling their schedules and deciding which classes to take, professors evidently treat this session as a dramatic academic trailer for their course. They have the feel of a pop concert—all the greatest hits, relentlessly paced, delivered by a human cannon of energy—but instead of Beyoncé on stage, it’s a skinny white man with a ponytail who loves materials science.1
In my pandemic stupor, I don’t remember any of these classes, except one: Robert Sapolsky’s Introduction to Human Behavioral Biology. His lecture was less about biology, and more about how we categorize things. Specifically, he argued that the discrete categories we apply to continuous concepts—from the colors we see and the sounds we hear, to the academic subjects we define and the races we project onto people—are both arbitrary and deeply consequential.
For example, different cultures and languages break the color wheel at different points. I look at the color spectrum below and see what I think of as red and orange and yellow and green, but I struggle to define the colors in between. Some cultures, however, draw boundaries in different places. People from these cultures can define my fuzzy spots, and can’t easily label what I clearly see as orange. Their eyes aren’t different; they just use different categories.

In other words, the categories we create, though necessary to keep us from being overwhelmed by this infinite spectrum, affect what we can actually see.2 The artificial boundaries we define eventually come to define us.
Those of us working in data spend a lot of time looking at our own incomprehensible expanse: The ever-growing landscape of data tools. To make sense of it, we draw a lot of boundaries, categorizing things as ETL, and augmented analytics, and orchestration, and social analytics, and a host of other names in between. When we talk about this landscape, these are the lines we debate.
These, however, are not the only fences. Another set of invisible borders carve them up, gerrymandering our maps in ways that are much more profound than the contested boundaries between BI and data analytics platforms, or data monitoring and data management. It’s the line that splits tools between those that are for “technical” users and those that are for everyone else.
No ecosystem diagram shows this; the market cares about the problems that need to be solved, not the means by which it’s done. Regardless of how we interact with a transformation tool, for instance—with code, with a point-and-click interface, with three-fingered gloves, with tiny motorcycles on graph paper—it’s still meant to transform data.
But, because of the implicit technical divide in the industry, data tools are almost always designed and sold for one audience or the other. Countless data tools advertise which side they’re on, often on A1, above the fold:
At the top of Stitch’s homepage: “Analysis-ready data at your fingertips...no coding required.”
How dbt Labs defines dbt: “Now anyone who knows SQL can build production-grade data pipelines.”
A headline for Metabase: “Exploration without the SQL barrier.”
The second line about Hex: “Work with data in collaborative SQL and Python notebooks.”
Precog’s product page: “The fast and simple way to load data from any source to any destination in minutes with zero coding.”3
As much as the problem it solves, we characterize a tool by who it’s for—analyst or business user; technical audience or “everyone.” Individually, this makes sense. It’s targeted marketing for a focused product. Companies choose their ideal customers, and build products for those profiles. Collectively, this makes a continuous technical spectrum discrete, a simplification that causes us to forget how important it is to build products that operate across the full range.
Though this is true for every meta-layer of the stack—ingestion, transformation, operational analysis—I’m particularly familiar with the problem it creates for the consumption layer of analysis and BI.
Historically, the consumption layer’s architecture looks something like the diagram below. Data is used by two groups of people, bifurcated along a technical boundary. One group, typically represented by analysts, data scientists, and engineers, use tools powered by SQL, Python, and R to answer strategic questions. The second group, vaguely defined as business users, work in code-free BI platforms backed by data models built directly into the tool.
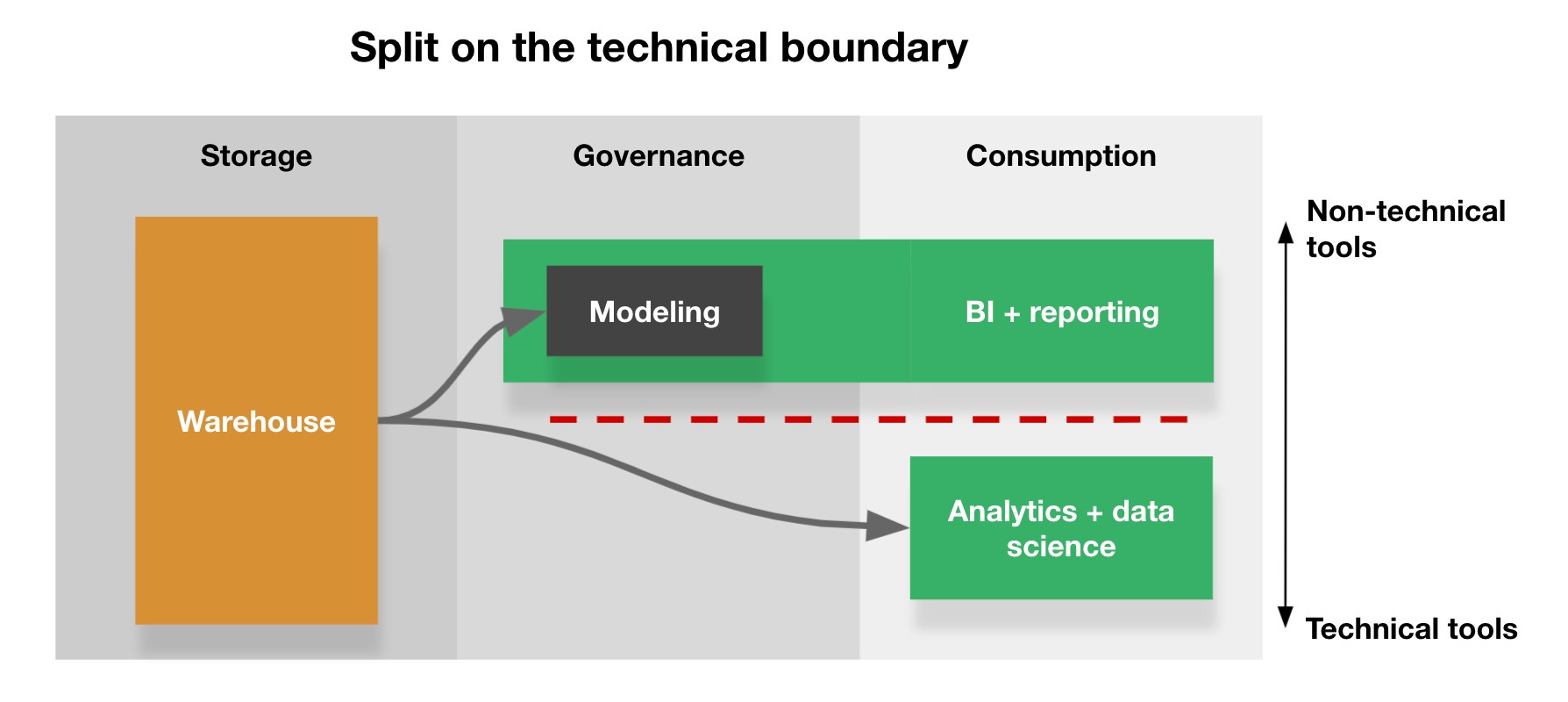
There’s a huge problem with this architecture: This isn’t how data is actually consumed. The line between BI reporting and analytical research isn’t a hard line; it’s a fluid, shifting continuum. Answers to one-off questions turn into recurring reports; reports are often the building blocks for key executive dashboards; dashboards are enriched with ML-powered forecasts; changing forecasts generate questions that need to be answered with bespoke SQL queries; elements from all of these assets get added to sales decks, shipped off to operational systems, and shared with customers. And everyone, from analysts building dashboards for executives to marketers asking data scientists for in-depth assessments of their most recent campaigns, has to work together at nearly every stage of development. As Anna Filippova recently highlighted, we have to “put aside skillset dichotomies, and learn to feel comfortable in the space between.”
But because we’ve trained ourselves to think in a language that defines everyone as technical or not, we’ve cut the world in half. Like a city divided by a poorly drawn political boundary, our method for consuming data is split by an arbitrary technical line that makes it extraordinarily difficult to cross a border that we frequently need to cross.
This has real consequences. For much of Mode’s history, we struggled to define which side of the wall we were on. Sometimes, we released a “powerful set of new tools for code-free data exploration;” other times, we built a tool kit for every analyst powered by “SQL, Python, R, or Javascript.” Though neither identity felt right, these were the territories available to us. Undoubtedly, the quality of what we built suffered from this confusion.
Eventually, we realized that the issue wasn’t our answer, but the question we were asking. The modern data stack doesn’t need a BI bucket and a data science bucket; it needs a unified consumption layer. To do our job well, we have to overcome the technical division, not be defined by it. Analytical needs don’t end at the code’s edge.4
Other parts of the stack follow the same pattern. Despite analysts and data scientists needing governance just as much as the users of a BI tool, we’ve interwoven governance into reporting tools; the invisible technical wall has proven to be higher than the often-discussed functional one. A better architecture (and one that we’re slowly twisting towards) would manage governance globally, from data modeling to metrics management. While most governance tools are code-oriented, these same tools should integrate code-free methods if there’s demand for such an interface.

Our implicit need to categorize tools at technical or non-technical holds us back in other ways. For years, people have been predicting that an explosion of vertical-specific applications (e.g., tools dedicated to sales analytics, customer success analytics, and so on) is just around the corner. It hasn’t happened. The problem, I believe, is that vertical tools like forwrd.ai don’t help us learn new things; instead, they’re code-free recreations of what analysts already do. Vertical-specific equals analyst-free, and analyst-free equals code-free.5
We should instead build for verticals by making it easier for analysts to work in those verticals. Rather than building a code-free way to analyze customer satisfaction, a customer success analytics tool should make it easy for analysts to collect and enrich data on support interactions and customer calls. Real advancement comes from removing friction between analyst and expert, not by replacing analysts with a limited code-free AI.
By doing the latter, we gerrymander our already complex landscape further, creating fractal after unmanageable fractal of unnecessary categories and subcategories. The result is, as Erik said, bad and hard to use. The sooner we see the space as a spectrum, and not a thousand discrete colors, the sooner we can build a better experience for everyone.
Lest you think I’m making fun of these videos, I am writing a post about minor fads in a minor niche of a nerdy industry where my lede—my hook, the best thing I could come up with for keeping your attention—is me telling you a story about me watching these videos.
This also affects how we think. At the start of the lecture, Sapolsky posed a question: What “causes” a person to behave abnormally? Is it their biology, developed over millennia of evolution? Their individual genetic makeup? Random psychological variation in the operation of their brain? Chemical changes in their hormones? The answer, according to Sapolsky, is all of them. These characteristics exist along a long intertwined spectrum that can’t be disentangled. But we get hung up on identifying singular causes because those are the academic disciplines—the categories—that we’ve created, and they’ve become the only way we can see the problem.
If there was ever a tool where code-free should actually mean magic Tom Cruise gloves, it’s Precog.
Even Gartner, which built a $25 billion dollar company by categorizing things in arbitrary buckets. is seeing the same thing.
BI itself reflects a similar dynamic. Self-serve tools are often designed as a code-free clone of how analysts work, even though this isn’t what most people who use self-serve tools want.
This is a really good read Benn. I believe everybody is technical at some level and we should all just replace the term "non-technical" with "less-technical".