

The ghosts in the data stack
An OLAP cube exorcism.

Data, Vicki Boykis tells us, is full of ghosts. Teams, organizations, and the analytics industry at large are haunted by implicit knowledge—knowledge that “exists within expert communities but is never written down." What it actually means to clean data, how to navigate the politics of influencing decisions, how to evaluate and purchase software—these are the things data professionals need to know but are never taught. And they’re the things that, once you discover, you forget how you learned.
OLAP cubes are another such ghost. Despite being a foundational piece of data technology, they’re mostly ignored by today’s data community. Despite being frequently referenced in marketing white papers, technical blog posts, and Gartner’s numbing cocktails of buzzwords and acronyms,1 OLAP cubes are uncomfortably difficult to define. Wikipedia offers a brief, self-referential definition—an OLAP cube is a multi-dimensional array of data—and refers us to an academic paper on databases for more information. OLAP.com, a website presumably dedicated to the promotion of OLAP cubes, tells us what they do (“a data structure that allows for fast analysis”) and what they’re not (OLAP is not OLTP).
Last year, Claire Carroll, motivated by exactly this ghost—she quotes a Twitter user who says “the ratio of ‘number of articles I have read about OLAP cubes’ to ‘amount of understanding I have of them’ is truly outrageous”—finally gave us a worthwhile definition. OLAP cubes are just tables, but tables structured in a very particular way.
When we think of a table of data, we instinctively think of it as a list of objects. Each row represents some discrete concept: a person, a purchase, a campaign donation, an action taken on a website, a pitch thrown in a baseball game. Not only is it easy to imagine how someone might collect this data—when a person buys something, add that purchase and various details about it to the ledger—but it’s also intuitive to manipulate. To count the number of individuals in a table of people, count the rows; to find purchases of a particular product in a transactions log, search for the entries for that item; to calculate the average donation from a list of campaign contributions, average the “donation amount” column.

As sensible as tables like these are, they can also get quite large—large enough that, twenty years ago, performing these simple operations on them was impractically expensive. Just counting the number of items sold in a table of purchases, for example, could take minutes or hours; more complex calculations, like computing median sales prices by state, could take far longer.
OLAP cubes—i.e., tables of a particular structure—were created to solve this problem. Rather than a list of objects, OLAP cubes are a table of metrics, or “measures,” pre-aggregated across nested layers of groupings, or “dimensions.” In the example below, the table of raw purchases is aggregated by month and state. There’s a row for each possible combination (say, January and California, or February and Ohio); each row includes metrics on that pairing, like the number of items sold and the total amount they sold for.

While this table itself isn’t directly useful, people can aggregate it again to produce more traditional reports. If you want to count the total number of purchases, sum the column of items sold. If you want to tally sales in California, filter the table to just the rows where state equals California. And for more complex operations, you can aggregate the data across multiple steps. To find the average number of items sold in a month, first sum the table by month to create a twelve row table of total items sold in each month; then average those totals into a single number.
This is more complicated than working directly on top of the original table, but it has one enormous benefit: It’s fast. No matter how many orders you process, the OLAP cube in the example above can never be more than 600 rows long—fifty states times twelve months. Computers, even those from decades ago, can easily work with tables of this size.2 As a result, most legacy BI tools were centered around OLAP cubes. BI administrators would define the cube in the tool, it would get precomputed on a regular cadence, and everyone else would create reports by manipulating and pivoting the data in the cube.
OLAP cubes were also limiting, though. Details get lost when raw data is grouped into pre-calculated aggregates. If you wanted to cut your data by a dimension that wasn’t precomputed, or if you wanted to see a list of the six purchases made in Ohio in January, you couldn’t do it. Compressing data, it turns out, isn’t lossless.
But there’s another, much less discussed downside to OLAP cubes: They’re very difficult to understand. Unlike a standard table, an OLAP cube doesn’t describe a tangible concept. It isn’t a list of objects or reportable metrics; each row, rather than representing a straightforward noun, is a combinatorial abstraction. It’s a middleman, an assemblage of computational scaffolding that can only be understood through its relationships to the raw data underneath it and to the reporting needs above it.
This structural weirdness is obvious in any BI tool that’s built on top of an OLAP cube. The screenshot below shows how Microstrategy presents their cube to its users. It feels like building a pivot table in Excel. But look at the fields: Customer, day, item, metrics, % change units sold, cost per unit, last year’s profit. What underlying table would have all of these fields?

No single table, as we typically conceive of one, would. And that’s the problem—OLAP cubes aren’t a normal table. They’re “multi-dimensional arrays of data,” and we can’t intuitively make sense of that.
This, I believe, is what makes OLAP cubes one of Vicki’s ghosts. You can’t look at one and understand it on its own. It has to be defined in context—in the context of the data it describes, and in the context of the technical limitations that necessitate it.
The OLAP cube is dead, long live the OLAP cube
None of this was supposed to matter anymore. As Claire mentioned in her post, OLAP cubes are no longer popular. Modern databases like Redshift, Snowflake, and BigQuery are large enough to count (and do much more complex operations) on top of very large datasets. People can now compute metrics on top of raw tables nearly as quickly as they can against OLAP cubes.
But, like any good ghost, though they may not exist in the physical form, OLAP cubes are spiritually very much alive.
Consider Looker, for example. Looker was one of the first major BI tools to fully discard the OLAP cube, and run its queries directly against the underlying database. In doing so, however, Looker changed how BI tools interact with data, but they didn’t change how people interact with BI tools.
LookML, the configuration language underneath Looker, is, in effect, a recipe for running a query. It defines how raw tables are related to each other, how they should be aggregated to compute various metrics, and the dimensions by which those metrics can be grouped. In an OLAP infrastructure, this configuration would be used to build an OLAP cube; metrics and reports would then be computed on top of that cube. When people use Looker to create a report, it does both of these steps at once. If you ask Looker for sales by month, it creates a query that extracts this metric directly, with LookML providing the instructions for how to do this.
Despite changing the engine, Looker’s UI is the similar to Microstrategy’s. Just as Microstrategy presents fields as collections of dimensions and measures to be explored, so too does Looker. And just as this presentation makes it hard to understand exactly what underlying object is being manipulated by these fields—it feels like a table, but definitely isn’t just a table—so too does it in Looker.
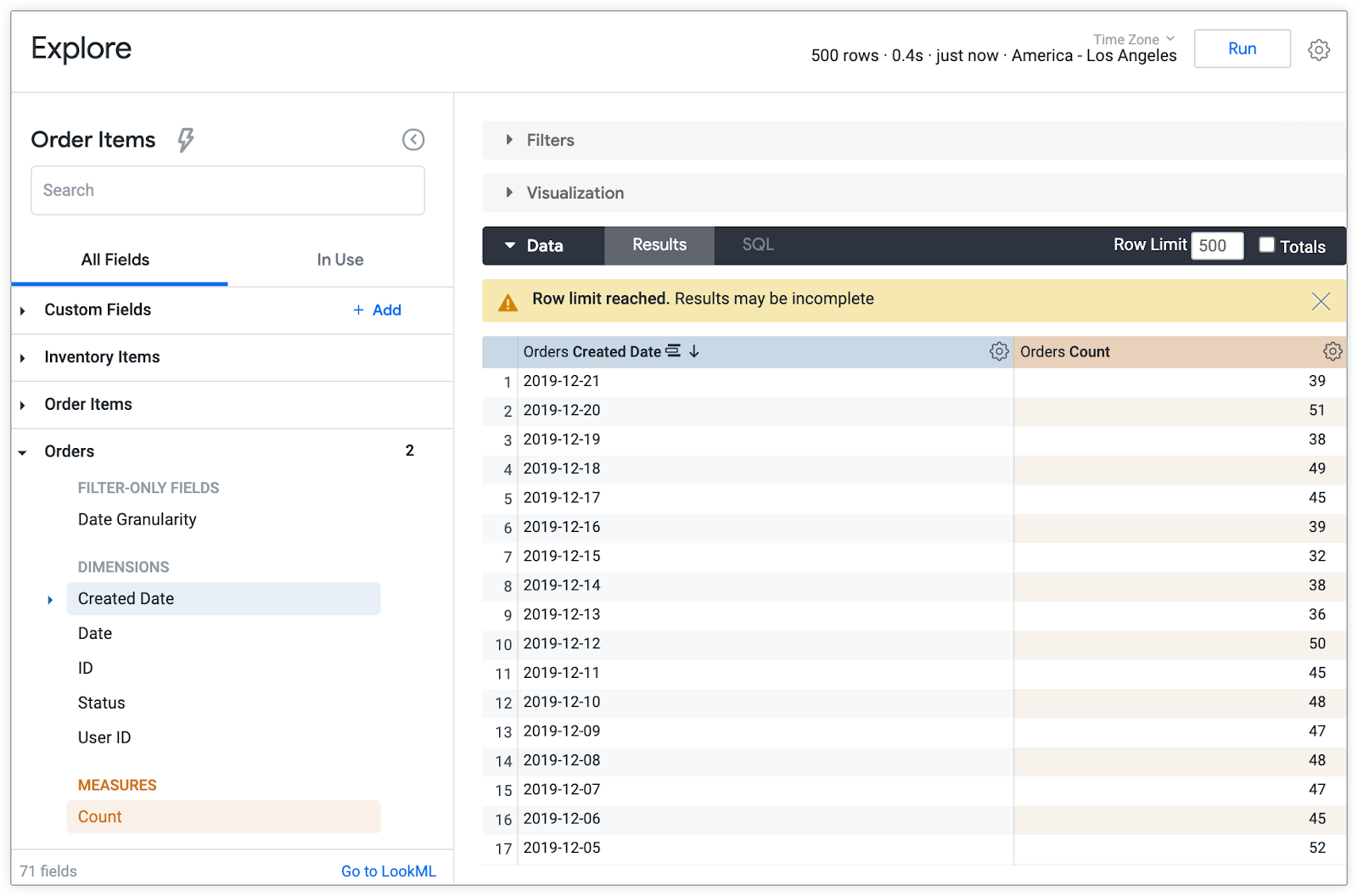
The BI landscape is full of interfaces like this. Tableau presents data in this way, as does Power BI.3 Even metrics layers like Transform function similarly: Configure how your data is structured, and present those results as dimensions and measures to be explored.4
On one hand, this makes sense. A LookML data model, like an OLAP cube or a Tableau extract, isn’t a simple table of users or customers. It’s a more complex data structure, and the UI reflects that. On the other hand, these data structures are confusing, and BI tools don’t have to create interfaces that mirror the architectures that sit underneath them. Rather than displaying data as we model it, we should display data as we use it.5
What we think of when we think of data
Early in my career, I worked for a think tank in Washington, D.C., where I helped write a weekly newsletter about the global economy.6 The posts were quantitative, and required a fair amount of data analysis. We relied on government data sources, and I, as someone who had never even heard of SQL at the time, relied on those sources’ drag-and-drop web portals to get the data I needed. I was, in other words, the business user to the government’s BI tools.
Two websites easily stood out at the best. The first was Fred, the data platform of the St. Louis Fed. What makes Fred great is its simplicity: It’s just a giant list of economic indicators. I didn’t know what the data sources behind Fred looked like, nor did I ever care. All I had to do was search for a metric.
The second website I liked was the IMF’s World Economic Outlook database.7 Unlike Fred, the IMF site didn’t ask you to choose a metric; it helped you build a dataset. You chose the category of economic statistics you wanted to see—you had choices like trade balances, financial indicators, and GDP and output statistics—and picked the countries and regions you wanted to see them for. The website would then generate a big table for you, with one row per country, and one column per indicator.
{kind=link}
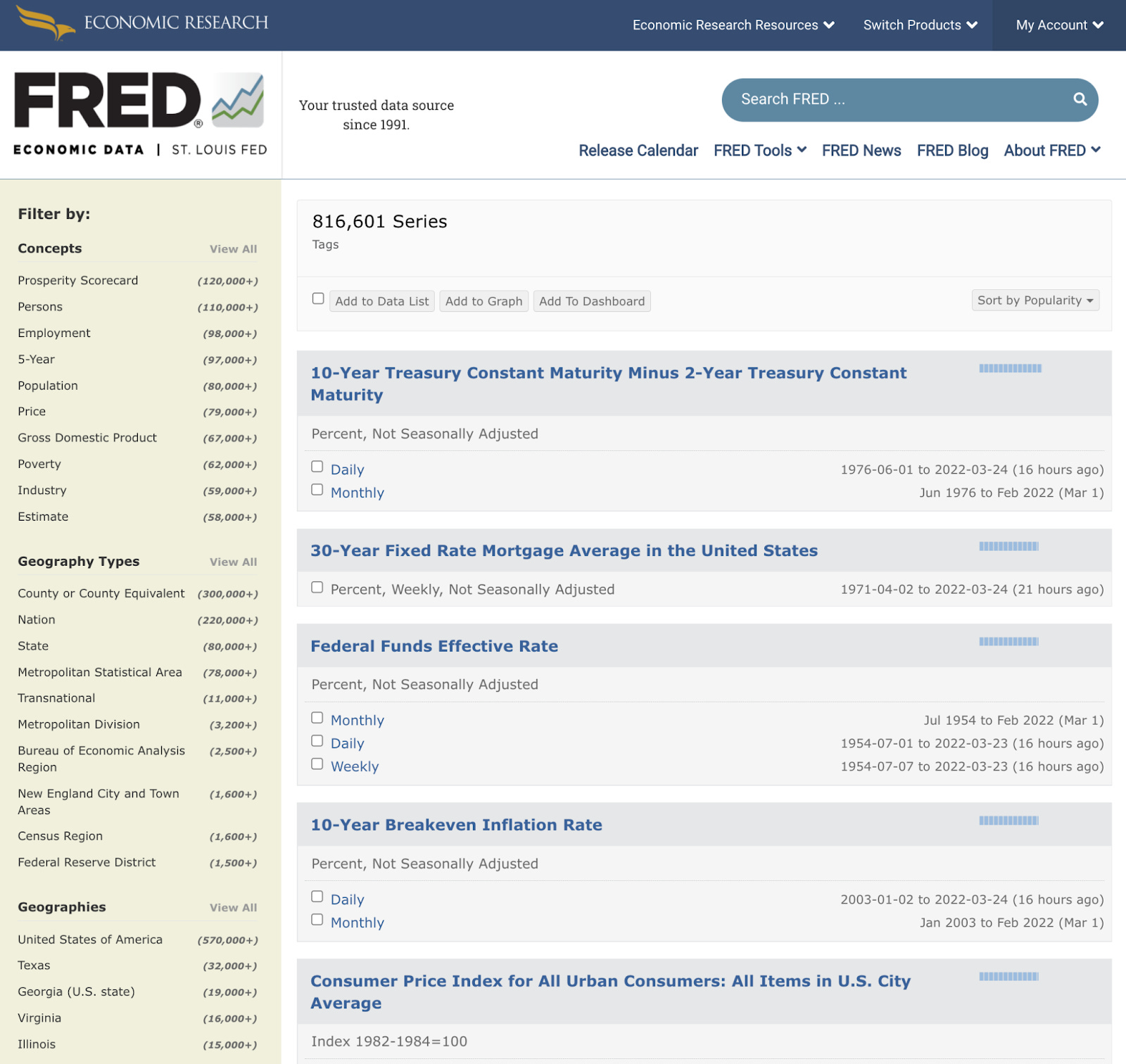

These websites were great because they presented data in the two forms that I understood it: As a metric, or as a table. While I’m sure the data underneath my requests was complicated and intertwined—there may have even been an OLAP cube or two in there—these websites hid all of that from me. Their interfaces matched the way I asked questions: Show me this metric, and help me create that list of countries.
Contrast this with the Census’s website, the worst government data portal. The Census offers a bunch of topics for you to “explore.” Because data is organized by source (i.e., the survey from which it was collected) and is presented in nested pivot tables, to use the site, you have to have some understanding of how the Census collects its data, and how different topics are related to one another. Even basic numbers, like population statistics by state, are difficult to find.8

Most BI tools look like the Census site. They expose data as it’s defined, through a thin GUI around a complex OLAP cube. A better solution would hide the implicit structure of the data behind the tool, and instead speak the language of those who use it. It would replace wide-ranging explorations with simple methods for finding metrics, and for creating flat, intuitive datasets.
This might seem like a step backwards.9 It constrains how much you can explore, and splits unified self-serve interfaces like Looker’s into two separate flows. But, our goal as tool builders—either as those who build products, or those who are creating reports and dashboards for our coworkers—should be to rid what we create of Vicki’s demons, and make things that can be understood with as little implicit knowledge as possible. After three decades of trying with OLAP cubes, it’s time to give up the ghost.
The description of this Gartner report is 208 words long. Thirty-eight are acronyms: SQL, SSAS, OLAP, OLAP, SQL, DBMS, BISM, SSAS, SSAS, SSAS, SSAS, OLAP, OLAP, BI, SSAS, OLAP, SSAS, GUI, SSAS, SSAS, BI, SSAS, OLAP, MOLAP, ROLAP, SSAS, MOLAP, ROLAP, UDM, SSAS, SSAS, SSAS, SSAS, SSAS, UDM, SSAS.
In practice, of course, most OLAP cubes are considerably larger than this. They contain more dimensions, like day of purchase and item purchased, and more metrics, like average sales price and total tax paid. But, contrary to my long-standing assumption that OLAP cubes were a special computational engine or some incomprehensibly complex matrix of numbers and Greek letters, larger OLAP cubes are structurally identical to the one above.
Mode uses a similar language of dimensions and measures. For better or for worse, however, the data underneath Mode’s Visual Explorer is typically a flat table returned by a query rather than a table structured like an OLAP cube.
Conway’s corollary: The experience of using any product will be a copy of the product’s data structure.
It’s Tuesday, let’s talk about the regional distribution of foreign exchange reserves.
Sadly, they’ve since replaced it with a much worse version.
More precisely, with the Census site, it doesn’t feel like you’re finding data as much as you’re creating data. And that’s exactly the problem.
Not least of all because I’m saying that the most advanced tech companies in the world should take their design cues from a ten-year old “data portal” built by a financial NGO.
Great post and thank you for addressing an oft-overlooked topic. I define databases by what I think of as their fundamental modeling unit. RDBMSs model everything as a relation (or table). XML databases model everything as an XML document. Hierarchical databases as hierarchies. Network databases as a directed acyclic graph. Multi-dimensional DBMSs (MDDBMSs) aka OLAP cubes model everything as hypercubes. A hypercube has (hierarchical) dimensions as edges and store metrics in the intersections -- the classic example being product, geography, and time. As in, show me sales (the metric) of widgets (product) in NY (geo) in 3Q20 (time). Not sure if that helps much but it tries to give a conceptual definition of them. They were initially launched to be generally useful but found only one real use-case: financial planning and budgeting apps which do a slot of slicing, dicing, and drilling (and aggregation) across dimensions. EPM vendors today all deal with the basic nightmare that OLAP databases have died off and, to my knowledge, only Anaplan has built a real substitute. You are correct that they were fast, trading precomputation and storage for speed. You are also correct that they are not relevant in the database industry these days and that, e.g., Microsoft is basically phasing SSAS out leaving something in place that almost but not quite replaces it if you're building an EPM application. FWIW, I don't find the cube-viewer interfaces counter-intuitive; Cognos made a fortune selling PowerPlay for years which was a cube-viewer. At BusinessObjects, where I worked, we tended to build cubes on the fly (which size limited them) and presented a more dynamic reporting interface as opposed to a slicer/dicer interface which people, to your point, seemed to like better.
https://open.substack.com/pub/benn/p/ghosts-in-the-data-stack?r=4fyhb4&selection=175e3ca1-134d-4027-99a9-d4cefd1f2236&utm_campaign=post-share-selection&utm_medium=web
Revisiting this paragraph in the age of LLM 2025 gives me chill