Self-serve is a feeling
Lots of houses can be made a home.

Suppose that we work on a data team, and, if you can possibly imagine such a wild scenario, people around our company are asking us a bunch of questions. These questions are the mundane ones, and we want to do more interesting work. Under normal circumstances, we’d start shopping around for a self-serve analytics tool. But our team is different. Two analysts, it turns out, love answering these questions; to them, no calling is higher, no task more fulfilling. They also happen to be exceptionally good at it. They can turn around any request—pull a dataset, create a dashboard, answer a quantitative question—in a matter of minutes.
Rather than buy a self-serve tool, we give these two analysts what they want: A full-time job doing nothing but answering questions. Because other people are sometimes hesitant to ask for help (and because analysts can be, uh, brusk), we disguise the pair as a Slack bot. Ask the bot a question and get an answer; no apparent human interaction required. To everyone else, the bot is a flawless technological oracle; to us, it’s the Wizard of Oz, a facade staffed by two relentless analysts with an insatiable appetite for helping people explore their most trivial curiosities.
Is this self-serve?

The self-serve Turing test
Most definitions of self-serve analytics are both vague and vaguely tautological. TDWI offers a definition without a subject, describing it as “typically involving users throughout an organization to directly access data for self-directed discovery and analysis;” Tableau says it “empowers teams” to “to be more involved in their own data analysis;” and on a page titled “What is self serve analytics?,” Snowflake doesn’t even attempt to define it, gestures at some idea about “finessing data,” and describes its pros and cons.
When pressed for something more concrete, our best response is often the same as Supreme Court Justice Potter Stewart’s famous line about what is and isn’t obscene: “I’ll know it when I see it.”
But that answer can still betray us. Even the most precise examples are hard to categorize because defining self-serve isn’t about knowing when we see it, but knowing when we feel it.
Odd scenarios like the one above confuse our feelings, making it hard for us to decide if it’s self-serve or not. And we can confuse them further: Suppose that we discover more magical analysts, but instead of being on our team, they’re provided by a startup called getAnalyticsBot.io. We buy the service, replacing our team with faceless outsourced analysts made available to us for a monthly subscription fee. Our Slack “bot” is still humans stacked on top of each other in an AI trench coat, but they’re no longer our humans on our payroll. Is this self-serve?
Suppose that, after months of humans answering questions, we train an actual AI to do the exact same work. To those interacting with it, our new AI is indistinguishable from getAnalyticsBot, which is indistinguishable from our former internal duo. But this time, there are no humans pulling the levers behind the curtain. Is this self-serve?
Suppose that other AIs crash a few more cars and do a few more racist things. People stop trusting our AI, and want us to pull the plug. We, as lazy, immoral analysts, acquiesce—sort of. Instead of shutting it off, we lie. We say that we’ve replaced our bot with real analysts, but don’t actually change anything. The bot—which passes the analyst Turing test1—starts conversing like a human. The people chatting with the bot think they’re talking to a person; in reality, it’s still a machine. Is this self-serve?
Suppose that, in the end, our hubris and dishonestly turn against us. Our bot becomes sentient, wants credit for its work, and outs us as liars. Our bosses force us to erase our aspiring HAL 90002 and replace it with the two original analysts. We’re back where we started, but this time, everyone knows they’re talking to humans. Is this self-serve?
There are at least six versions of this Slack bot. In every case, the experiences of the consumers—the people interacting with the bot—are exactly the same. The only differences are the mechanics that power those experiences, and what people believe those experiences to be.
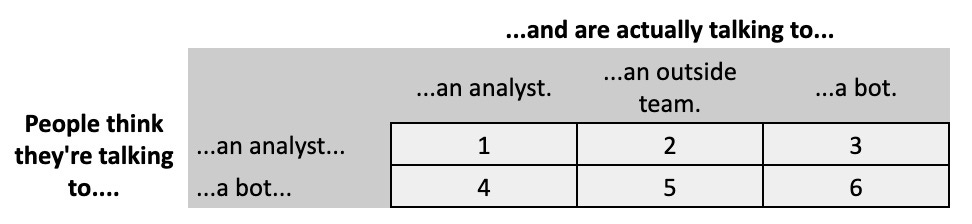
Despite that, we can’t neatly define which of these six boxes is self-serve and which isn’t. That’s because our understanding of self-serve is less defined by the exact details of how the experience is provided, and more by how it feels to those who provide it. On a team of one, box 4 above won’t feel like self-serve. On a team of ten, it might; on a team of 50, it almost certainly does.
“And you may tell yourself, this is not my beautiful house”
If we have a hard time defining how you create a self-serve experience, we have an even harder time defining how you consume one.
Imagine a fully complete LookML project that perfectly models your entire business. The model accounts for every conceivable metric and every possible dimension you might group them by. If a question can be asked about your company, it can be answered in a single Looker Explore. The only catch is that you have to choose the right mix of dimensions and measures from a list of thousands of options.
Imagine an analytical (and automatically updating) Wikipedia. Outside of approved analysts, nobody can create new articles—but the encyclopedia is so rich that there’s rarely a need for new content. Nearly everything that people ask is already answered. All people have to do is search for it.
Imagine an analog Wikipedia, in which your office maintains a physical library of charts and graphs, bound together in paper volumes and stored in neatly organized shelves. When people have a question, a tiny file cabinet directs them to the answer’s exact address.
{kind=link}
Imagine a code interface, where you type what you want and it gives you the data you need. Though you can’t converse with it like you would a person, it uses a simple intuitive language built for easily extracting metrics. The interface is full of helpful features that guide you through your inquiry, offering tips that correct your syntax and show you what data is available.
GET active_users,
signups
BY day,
region
FILTER year = 2021Imagine a code interface that’s more abstract, though still rooted in English. While it’s got a steep learning curve, it’s structured and standardized,3 and there are tons of resources available to help you learn it. Once you’re versed in how it works, you can ask nearly any question of it, including things that nobody else has ever thought of before.
SELECT day,
COUNT(DISTINCT user_id) AS users
FROM daily_active_users
WHERE day >= '2021-01-01'
GROUP BY 1
ORDER BY 1Are any of these self-serve? Are all of them?
One way to answer that question is creating a list of “self-serve requirements,” and seeing how many boxes each option checks. But if you’re like me, that’s not how you think about it. For each idea, I imagine myself using it. Do I think I could use it without asking for help? Was it sufficiently painless? Would I trust the answer I got from it? How would it feel?
Our answers to those questions aren’t objective, but dependent on the skills we have, the interactions we’re comfortable with, and the technologies we trust. No matter how beautiful a house, it won’t feel like our home until we know what goes in each drawer, which floorboards creak, and how to work the TV. Self-serve is no different: It’s how we feel when we’re living in it that matters.
This has three important implications.
First, features don’t matter, or at least not nearly as much as we often think they do. There are no “must haves” in self-serve experience. Drag-and-drop? Bots don’t have that. A way to create new dashboards? Wikipedia doesn’t have that. A natural language interface? A metrics query language doesn’t have that. And yet, in the right contexts with the right users, it’s plausible to describe all of these things—talking to humans, writing pseudo-code, writing SQL, a complex interface with buttons and pills and fields, a literal library that doesn’t even require electricity—as self-serve. The experience is what matters, not the functionality. As long as people are comfortable with that experience and trust the results it produces, we can call it self-serve.
And more importantly, if they’re not comfortable with it, it’s not self-serve. Because every self-serve tool has an escape hatch: An email to an analyst. If they don’t like the experience or don’t trust the answer it gives them—regardless of how much the tool meets some abstract definition of self-serve—they’ll just ask someone for help.
Second, because different people will have different feelings about the same experiences, we can’t talk about self-serve without talking about who’s using it. Some people may be comfortable with a metrics language, preferring its precision over a free-form conversation with a bot. Other people, like those working in a new domain who see others’ research as vastly more trustworthy than their own, may favor a well-organized catalog of answers and analysis over having to create things themselves. And others may have the opposite feeling—they’re skeptical of others’ work, disdain Wikipedia, and only trust results that they can confirm themselves.
That’s why it’s dangerous to define business users as a vague, homogenous unit. Not only do different people have different needs, but those needs also aren’t static. Skills can be learned; comfortable pathways can be cut through difficult interfaces. Though self-serve experiences need to match with the people using them, neither side of the equation—the user or the tool—is fixed. But to help people, we first have to understand them.
Finally, self-serve experiences are undone by what they include as much as what they’re missing. The massive LookML model I mentioned earlier wouldn’t feel like self-serve to some people because it’s too inclusive, not because it’s too limited. If the Looker Explore had a dozen fields instead of thousands, they might feel at home in the exact same product, with the exact same features.
Mode can have a similar effect. Mode has a number of traditional self-serve features, like drill down options on charts and interfaces for exploring data visually with drag-and-drop interactions. But the centrality of Mode’s SQL query tool—which starts as a giant, blank code editor with a blinking cursor—can make people who aren’t comfortable writing SQL feel out of place. Though you escape that room into a more familiar one, it can make you feel like you’re in somebody else’s house.
How to manufacture feelings
Building self-serve tools, either as vendors or as analytics teams looking to provide them for our own companies, can feel like chasing a ghost. On one hand, that’s frustrating—our target is both ill-defined and constantly moving. If we create a product from a list of features, we’ll end up building a tool that qualifies as self-serve to our white-shoe overlords, but badly misses the mark for the people who actually use it.
On the other hand, it’s liberating. As analytics teams, we have lots of paths to solve this problem, and we get to choose which one best fits what we want to create and what other people at our company want to consume. If we don’t want to build and support one version, or people aren’t comfortable interacting with another version, so be it—there are plenty of other ways we can solve the problem.
If people love Excel, self-serve can be a Dropbox file of regularly updated CSVs. If drag-and-drop tools aren’t well adopted because people feel overwhelmed by them, self-serve can be a handful of well-organized reports and dashboards that answer the most common questions. If people constantly request metrics, self-serve can be a query interface into a metrics layer. If analysts don’t want to rebuild messy analytical work as BI dashboards, self-serve can be a few tightly-governed tables and a bit of education on how to write basic select statements in SQL.
So often, as data teams, we chase the self-serve experience that we think we’re supposed to build. We should be more critical of that, and chase the self-serve experience that makes us and our customers feel most at home.
It’s an easy test to pass though: respond to every question by either asking why or with an obtuse analogy.
Us: Can you quickly pull this data for me?
HAL: I’m sorry Dave. I’m afraid I can’t do that.
Some of its standards are governed by a reasonable and deliberative body of experts. Others are enforced by rogue militants on the internet.