

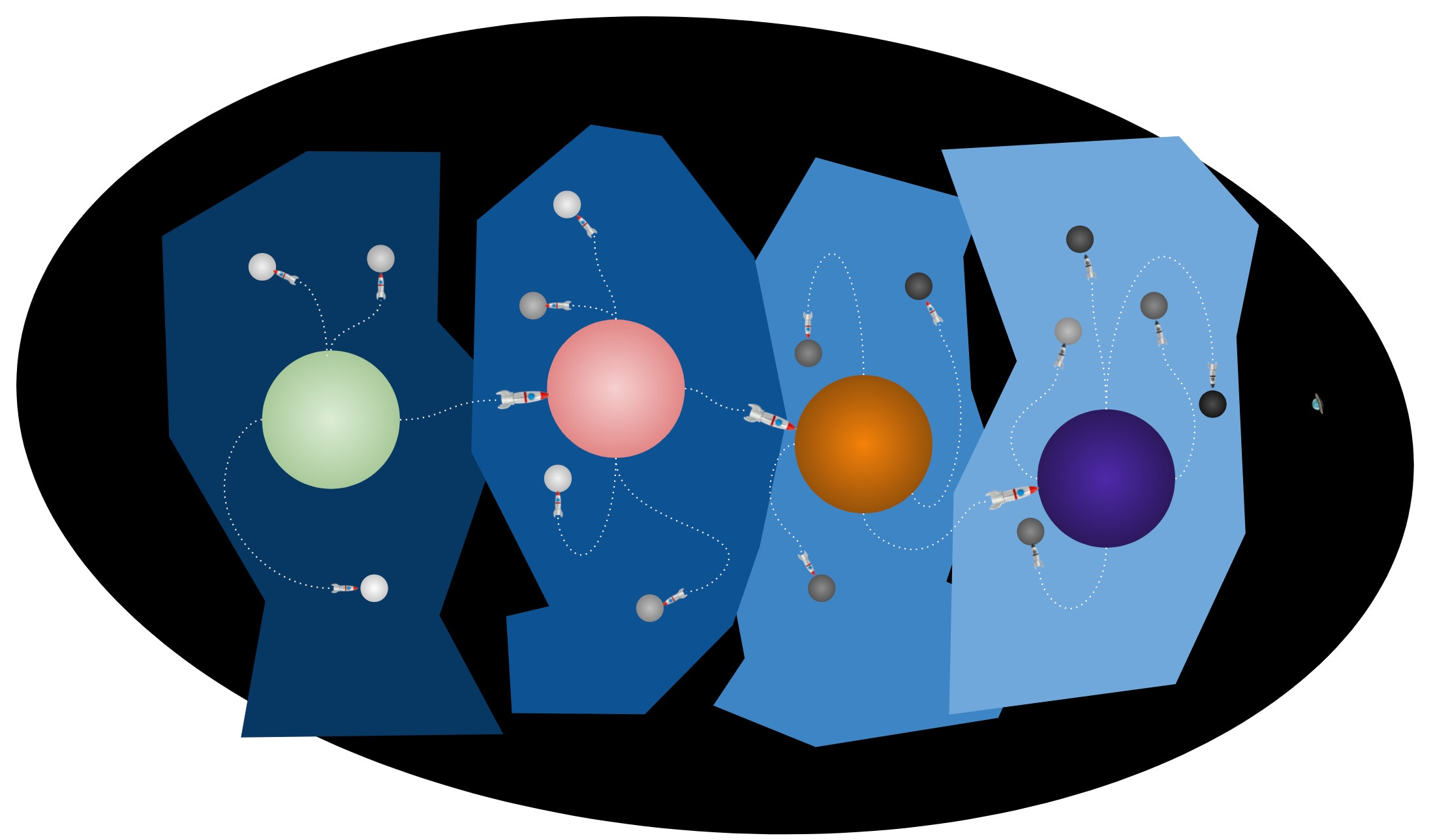
The intergalactic data stack
Falling further into the BI black hole—and charting a course out.
They say a big part of working in data is telling people no, and I wasn't having it.
A few years into building Mode, we were standing on a growing pile of feature requests to improve our visualizations. People wanted more chart types, more ways to aggregate data, and more formatting options. Spending most of my time in support queues and fed up with constantly having to tell customers about frustrating limitations and annoying workarounds, I constantly bickered with Josh, one of Mode’s other founders, to start burning down the backlog. How hard could it be, I argued, to add rolling averages to a line chart?
Every time I pushed, I was told no. I was told that, while we could build this option and that checkbox, these solutions were bandaids. Data visualization is both wide and deep, and tacking on whatever people are asking for today will only make it harder to build what they’ll want tomorrow. We needed to build a system.
Over the next couple years, two things happened. First, we built the system. Second, I realized that Josh was right.1
Josh was right because visualizations are the ultimate cookie. No matter how much a visualization technology can do, people will want more.
The first requirements are easy to anticipate. Give people a line chart, and they’ll want to add another line on a second axis. Then they’ll want to turn one of the lines into a bar chart; the bar chart will need multiple series; first stacked, then grouped.
If the chart is a time series, they’ll then want to group data by different intervals: by day, by week, by month. But do weeks start on Sunday or Monday? They’ll want to choose. Which time zone are dates grouped in? Can you exclude weekends? Can you treat incomplete periods differently?
At some point, the requests get more complicated. Plotting raw data isn’t enough; people want to derive running totals. And rolling averages, over 7 days; over 14 days; over 90 days—and, in cases where days are missing, interpolate those values as zero. But also let them sometimes choose to ignore the missing values and treat them as nulls.
Standard calculations like these won’t be good for long though. People need to write custom calculations to derive new fields. They start basic enough—ratios, sums, fixed goal lines—but they turn into complex formulas for computing percent changes relative to the first value in a series; the last value in a series; the previous value in a series; the average of the previous seven values in a series; the average of the previous seven values in a series, but after ordering the series in a customized way.
Eventually, one chart isn’t enough either. People need faceted layouts, showing multiple charts in a grid—and each chart needs to support everything that one chart does. Only more, because once they have faceted charts, people want to compare values across each facet. Each chart should represent the percent of the total values of all the charts in the grid. Or the percent of all the values in each column of the grid. Or each row. Or the whole grid again, with separate totals for each series.
And all of this has to be formatted. Colors need to be semantic: red is low; green is high. Or green is low and red is high. Colors need to match brand styles. Fonts need to match brand styles. Add labels to every data point. Add labels that only highlight the important data points. Axes should show every three months; change monthly labels to quarters; to fiscal quarters; dates have to be formatted in European styles; currencies should be euros; use spaces instead of commas; use periods instead of spaces. Round the edges of the lines. Interpolate the missing data points. Round the corners of the bar charts.
And render it all, quickly, using a code-free UI that doesn’t require special training, on top of gigabytes of data.
I didn’t anticipate any of this, but our early visualization team did. They saw that we couldn’t keep hanging feature after feature on our basic charting tools, like trying to find some ledge to balance another piece on a teetering Jenga tower. We needed—and the visualization team made—a foundation that left a place for all of these blocks.
The blueprint isn’t the experience
Despite the huge divergence in actual outcomes, the differences between what I was asking for and what the team built were mostly in implementation, not architecture. We all wanted to combine a better workflow for analysts with a drag-and-drop tool for everyone. Our sketches of Mode’s architecture were identical: from SQL IDE to visualization tool to reports and dashboards.
But blueprints aren’t experiences. We weren’t building diagrams; we were building a way to explore and share data. In creating that experience, the tactical details are just as important as the arrows we draw from a box labeled SQL to a box labeled chart.
When Mode’s visualization team told me to wait, they were thinking about this experience. They knew that building a tool with a low ceiling—what I was tacitly proposing—would wreck the experience people actually wanted. Whenever someone hit a wall in what Mode could do, they’d have to copy their work into another tool. If they wanted to make richer visualizations, they’d reproduce everything in Tableau; if they wanted precisely formatted charts for an executive deck, they’d have to do it in Excel; if they wanted an obscure chart type, they’d have to write the code to build it themselves. And they wouldn’t care about the reasons for Mode’s technical limitations, no matter how high we stacked our soapboxes when we explained it to them.
BI is short for big
I was reminded of this period in Mode’s history during the recent debate about the future of business intelligence. On one side of that debate (the side I started in), BI is transitioning from helping non-analysts answer their own questions with code-free interfaces to a universal consumption experience. Rather than splitting self-serve from advanced analytics workflows, BI should include both, in one singular application.
Others disagree, arguing that governance layers (e.g., dbt, a metrics layer, the data mesh, a data OS) make this monolithic product unnecessary. Instead, consumption tools should be thin solutions that target specific verticals and use cases. Because the range of consumption problems is too big for one tool, the infrastructure layers of the modern data stack should act as a platform that lowers barriers of entry for new, app-like solutions.2
Emotionally, I’m in the decentralized camp. Splitting BI into dozens of specialized apps, all coordinated by an OS-like layer underneath, feels both elegant and egalitarian. The parallel with mobile apps (an analogy I’ve already endorsed) is also compelling, and fits neatly into the grammar of Silicon Valley. For entrepreneurs, a data operating system is fertile soil for innovation; for VCs, it’s a marketplace for money to be made. Everyone loves a platform.
But the harsh—and sometimes frustrating—reality that Josh beat into my head makes me skeptical of that idealized vision, for three reasons.
First, any borders we put on our visualizations capabilities at Mode—if, for example, you could create line charts, but you had to go elsewhere to create faceted line charts—would feel, to our users, artificial. The technical reasons for the boundary are irrelevant; all people care about is creating the charts they need. For them, a gerrymandered visualization stack is a bad experience.
The same is true for BI. People don’t want to hop from Hubspot to Amplitude when they’re trying to figure out which product features recent webinar attendees are using; they don’t want to recreate a notebook’s output in Looker to make a dashboard out of Prophet forecast. The boundaries we put between these different types of data exploration—vertical-specific analysis, Python analysis, SQL analysis, pivot table analysis—are technical, not experiential. To the extent that we categorize these uses as discrete, we do so because our tooling compels us to; in practice, they’re overlapping bubbles on one long spectrum. We should ship an experience that mirrors what people want to do, not one that mirrors the org charts of the teams helping them do it.
Second, just as Josh and I drew similar architectural diagrams that ultimately mapped paths to two very different destinations, a neat theory about a data OS is a long way from a coherent solution. We should be skeptical of these diagrams—including my own—until they provide more specificity about the actual experiences they’d create.
Huy Nguyen called me out on this recently, saying these conversations are “speculative and interesting but not instrumentally useful.” Fair—as Huy says, the pertinent question is how do these diagrams actually make people’s jobs easier or better?3
On that, we’ve got a lot of details to fill in about how we’d build a decentralized BI layer on top of a data OS. Consider just one example: cross-app collaboration. If, for instance, I want to put my A/B testing results in a product analytics dashboard, how do I do this? Or if I create a chart in Tableau, how can I build on it in my forecasting tool?
One potential solution is a shared protocol built on a backbone of SQL queries and visualization configurations. Which brings me to another lesson I learned from underestimating visualizations for several years, and the third reason I’m skeptical of decentralized consumption apps: Visualizations are really hard to build. Tableau, to take an obvious example, is breathtakingly far from being a simple charting configuration. All of the things it can do—derived calculations, facets, formatting, animations, and much more—are both complex and, to many of Tableau’s customers, necessary. Short of embedding it directly, there’s no reasonable way to port something created in Tableau into another product.
For this reason, I don’t think it’s feasible to make BI thin. Visualization on its own is a very heavy piece of technology, and that’s only a fraction of what BI tools need to do. For instance, they have to build permission paradigms that deal with not only the usual concerns about who can see, edit, and administer content, but also with an overlapping layer of permissions associated with underlying data sources. When granting someone edit access to a report implies that they can change a query about blog post traffic to SELECT * FROM all_the_salaries, it introduces a whole bunch of complications that most SaaS apps don’t have to address. There are similar challenges with versioning, collaboration flows, and other experiences that make a BI tool functional.
These problems aren’t straightforward. While it’d be great if they could be outsourced to a federation of apps, some systems, for better or for worse, simply function better under central management.
From ecosystem to solar system
There is, however, a compromise to be had. In my original post about BI, I talked about the need for a “universal” consumption experience. That, as Ryan Janssen suggested, goes too far—and he’s right.
Consumption, instead, should be split into two categories. The first is generic exploration. This is the type of data consumption that starts with a business question and ends with a quantitative answer. Though the tools used in the middle may differ—Python, R, visual exploration, pivot tables, SQL, Excel—and the form of the output varies, the structure of this type of work is broadly similar.
In other cases, people need to solve specific problems. They want to analyze A/B test results; they want to examine the emotional sentiment in support tickets; they want to create financial forecasts based on standard accounting principles. Specialized tools are hugely valuable here—more valuable, even, than seamless interoperability with other tools.
To extend the cosmic analogy, this suggests that a universal tool isn’t appropriate; instead, we need a planetary one. We need a global exploration tool that works for most general uses, surrounded by satellites that solve specific problems really well.4
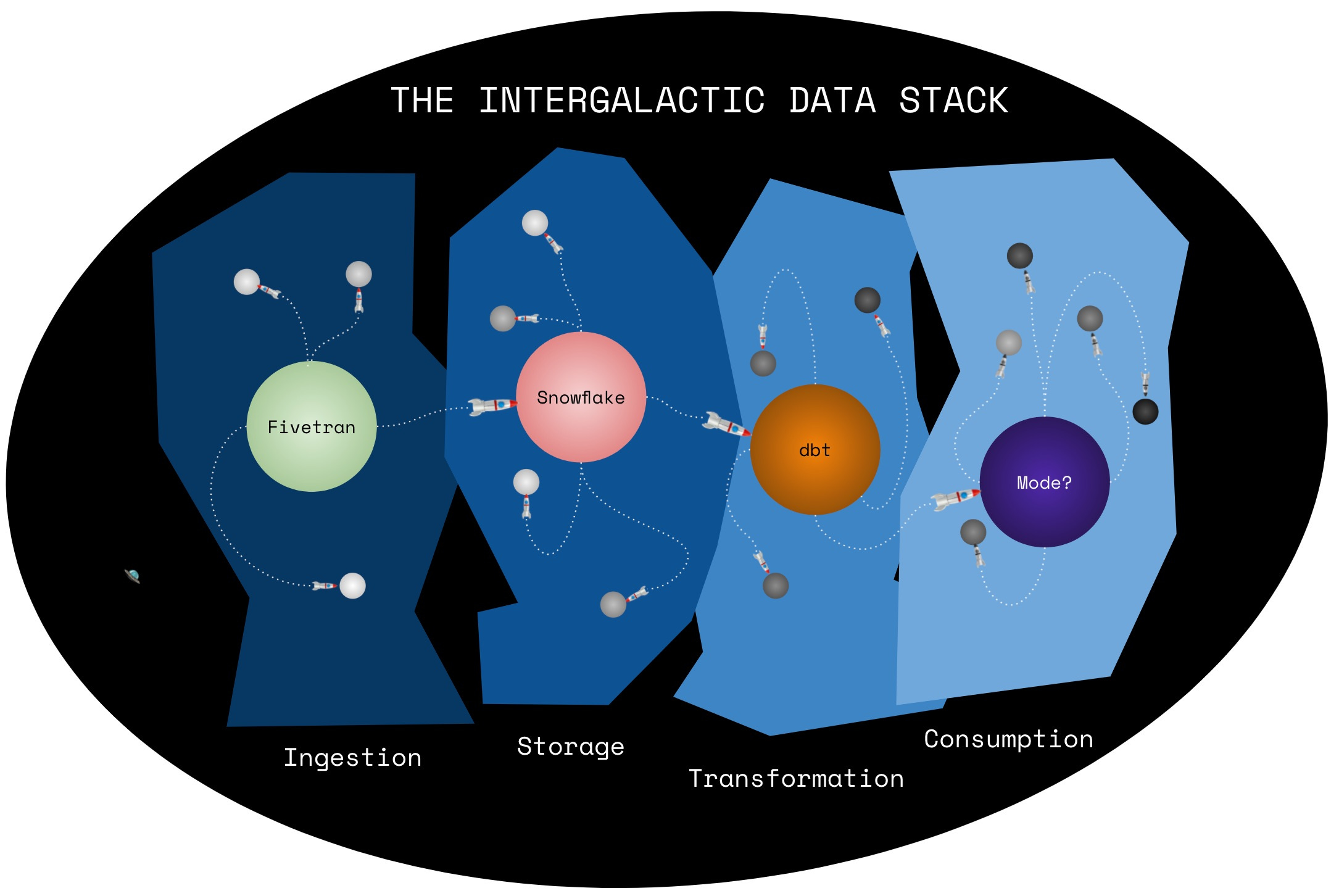
This structure is already emerging in other parts of the stack. Snowflake is the storage layer’s planet; specialized warehouses like Clickhouse are its moons, dedicated to particular types of processing. Tools that ingest obscure sources (and potentially reverse ETL services?) resolve around Fivetran; products like Zingg that handle specialized transformations orbit dbt.
The BI planet hasn’t fully formed yet. But that, I think, is what we’re gravitating5 towards.
A final thought on open source
There’s another timeline in which the consumption layer is both decentralized and open source. I’m hardly an expert in open source issues, and mostly don’t know what I’m talking about here. But I’m naively skeptical of this approach as well.
As best I can tell, open source ecosystems do a much better job building technology than they do building user experiences—and data consumption is, at its core, an experience. This, I think, suggests that a data OS could be open source, but the most important apps that sit on top won’t be. This is especially true for enterprise customers, who care a lot about problems like security and user administration that open source tools rarely address. Snowflake, which built a $90 billion database in a sea of free open source options, is proof of this.
I am optimistic, though, about the possibilities for app marketplaces in BI. I have a lot of questions about economics of that, but they’re beyond the scope of this post.
Right, at least, in his approach for building a visualization tool. There’s a debate to be had if this is the right decision for a business. Maybe for later, whenever this Substack makes its inevitable pivot from indulgent treatises about data to personal stories about building a startup in Silicon Valley. Consider this your warning.
You could argue that there’s a third camp that believes all of this should be automated. I don’t agree with this because business decisions are far too nuanced and complex to automate in this way. More on this later, perhaps.
This is why I’m bullish on dbt’s opportunity to become an operating system for the data stack. A data OS isn’t a new idea, and other companies have proposed things that are architecturally similar. For example, AtScale is building the universal semantic layer; Google is building the Dataplex; and The Modern Data Company is building the DataOS®. But dbt is already there, in people’s stacks, creating a universal governance experience that people like. It’s that experience, not a flow chart, that gives it such potential energy.
As I mentioned in the prior post on BI, this isn’t a claim of an unbiased observer. Because I believe in the value and inevitability of the self-serve and advanced analytics worlds colliding, our long-term aspiration at Mode is to be this planet.
Get it???
This is a great post. So many thoughtful problems to solve to make data "usable". I've experienced many of these working on data platforms at companies large and small.
I really like the planetary level reference. You mention the various layers and tools. BUT, I feel there is a human component that is missing. This is something I am actively working on. From my experience, many issues stem from the consumers of the data (via the consumption planet level) don't know what data is available (storage/transformation), nor where it comes from (ingestion) should they need to request a change.
The technology challenges are difficult problems to solve. It is a given we'll work on them as an industry. However, I feel there is a people problem involving collaboration and communication that is not being recognized. As I mentioned, I'm working on something that I felt a previous organization would have really benefited from.
I really enjoyed this post and look forward to learning from your future posts on DataOS, etc.
Thank you so much Benn for mentioning Zingg