The rise of the analytics pretendgineer
How to fix dbt. Plus, everything is spreadsheets, and Snowflake is bullish on B2B SaaS.

One way to think about a dbt model is that it’s a table. It’s easy to think this, because most dbt models do, literally, create tables in a database. A company might have a products table that’s imported from their inventory management system, a charges table that’s imported from their Stripe account, and a dbt model called orders that combines the two into a table that contains details about anything anyone ever bought from the company. That dbt model will be a SQL query; the output of the SQL query will be a table.
But another way to think about a dbt model is that it’s a function. The data team is trying to create something—in this case, a list of everything the company has ever sold—and the orders model takes two tables as inputs and produces a new table as its output. The model is a formula that contains a bunch of computational logic that describes how to do that calculation.
A dbt project, then, is roughly analogous to a program. Each model is a function. The functions can reference one another. And the functions’ authors layer them on top of each other, with the goal of producing a collection of tables1 that people can use to build dashboards and answer questions.
Of course, dbt Labs didn’t invent this sort of data modeling “program.” Prior to dbt, data teams used other tools to manufacture the datasets that people used to build reports and do analysis. But, the previous versions of these programs were hard to write. They were written in languages that are less accessible than SQL; they ran against databases that were relatively slow and relatively easy to break; the production datasets were sometimes complex and confusing objects like OLAP cubes. To create the orders tables in an Oracle Database 10g in 2004, you had to design a table was legible to Oracle’s BI tool, write your own CREATE statements that produce that table, hand-code things like transaction blocks to make sure your script doesn’t nuke the entire database or send it spiraling into some infinite loop, index your new table correctly, figure out somewhere to deploy the script, and then monitor the whole thing to make sure that a missing shrink operation doesn’t grind your 10g into useless brick. And if you had lots of models that used your orders table as an input, you had to figure out how to make sure they always run at the right times, in the right order.
It was hard. It took time to learn how to do it. One does not simply walk into orders tables; they take the Oracle 2 Day DBA course first.
The people who took those sorts of courses, however, didn’t just learn technical skills. They also learned about the art of data modeling. They learned how to organize and arrange the various functions in their “program” so that they’d be easy to update. They learned how to design efficient functions that wouldn’t crash the database. They learned how to structure the final datasets that they produced so that they would be easy to use. It wasn’t perfect, by any means, but there was a sense of rigor to the entire exercise. People wrote “definitive guides” about it.
dbt changed all this—mostly for the better, but a bit for the worse. People could construct data models in pure SQL; they didn’t need to worry about things like transaction blocks or table indexes or DDL; dbt handled the dependency graph between models and made sure everything always ran in order. Moreover, modern databases made everything much more durable—whereas an inefficient model might knock down an old Teradata warehouse or Hadoop cluster, products like Redshift and Snowflake could absorb it.
On one hand, fantastic. People can now write data modeling “programs” without the headaches of yesteryear. It’s cheaper, faster, and far less tedious. A hard thing became an easy thing.
On the other hand, though dbt made data modeling easy, it didn’t make it simple.2 The goal of the data modeling “program” is still more or less the same today as it was twenty years ago: Bring the meaning of data close to its surface. Transforming some hideous log of web events and mangled Salesforce opportunity records into a useful table that tallies how many active users are in every account is computationally convoluted. There are a lot of logical steps required to write those formulae. While dbt makes it much easier to write each one—each model is just a query, saved in a SQL file—it doesn’t really tell you how to bind them all together. Should you write one query that does it all? Six queries, each with some isolated bit of logic? Six queries, with each referencing a dbt macro? One choice will make the data modeling “program” efficient and tidy; the other will turn it into a sprawling briar patch of tangled dependencies and tech debt. One will simplify; the other will complect.
I have no idea which one is which though, partly because this is a toy problem and all made up, and partly because I—like the vast majority of dbt’s other users—were never taught how to write the program. We only learned how to write functions.
Benngineering
For a time, every time someone sent a support request into Mode, the customer success manager who owned the account submitting the ticket would get a message on Slack telling them about it.3 I wrote the code that powered the system. A webhook from Intercom triggered a script in AWS Lambda; that script went back to the Intercom API to retrieve more details about the ticket and called the Salesforce API to get information about the account that the ticket belonged to. A hard-coded if statement inside of the Lambda mapped Mode account reps to their Slack handles. Another function composed a Slack message that mentioned the rep and attached a link to the ticket. A final function sent the message to Slack’s API.
It “worked.” Slack messages got posted for most support tickets, and most messages mentioned the right rep. But, when an actual engineer—as opposed to me, a pretengineer, a benngineer—opened up the code to make an update, they were horrified. The entire “application” was a disorganized series of Python functions that had been haphazardly glued together into a Rube Goldberg machine of namespace collisions and intertwined logic.
I wrote it like this because I understand how to write functions, but I don’t know anything about programming frameworks. Proper Python apps are full of stuff like classes and modules and something called __main__; I do not know what any of it means. All I knew was how to jam a bunch of functions together—functions that took way too many inputs, because I didn’t know any other way to pass information from one layer of the program to the next. It was brute-force as software engineering (BASE).
—
Every time someone goes to www.benn.website, a Python application serves them a webpage. I wrote that application too. It’s a little better than the support Slackbot, but not because I became a better programmer; it’s better because I used Django to build it. Like Ruby on Rails and other web application frameworks, Django both helps you build stuff with Python and is very opinionated in its assistance. You are supposed to put certain parts of your program in specific places, and the app often won’t work if you do it differently. Because of this, benn.website is essentially a script, just like the Mode slackbot, but it’s a script with structure. And whenever I wanted to add something new—for example, “how can I use a single variable to control the primary font on my site?”—the internet (or ChatGPT) won’t just give me the code to do it; it’ll also tell me how to organize it.
Roughly, dbt is functions without a framework. There are official best practices, but they’re more suggestions than guardrails—and nobody wants to read the manual anyway. As a dbt project grows, the only thing keeping us from turning it into a spidering web of entangled models and duplicative logic is our own discipline and design sense. Which takes skills many of us never learned, because we never needed to.4
In other words, dbt’s explosive popularity turned a generation of data analysts into analytics pretendgineers. We all figured out ways to create lots of dbt models and glue them all together—dbt is very good at this, it’s very useful, and people are very creative!—but most teams did it in the same way I built the Slackbot: As fragile scripts, full of imaginative workarounds that are a little too creative for their own good. It all works, but man, there’s got to be a better way.
Everything in Alteryx
From this blog, last September:
There are, I believe, four well-defined categories in the data world. The first three are reasonably well understood: Warehouses, for storing the numbers; BI platforms, for graphing the numbers; and integration tools, for going out and getting the numbers.
The fourth category is basically “other.” It’s a giant pileup of somewhat related functions, like data cataloging, governance, lineage, observability, orchestration, transformation, and discovery.
From dbt Labs, two weeks ago:
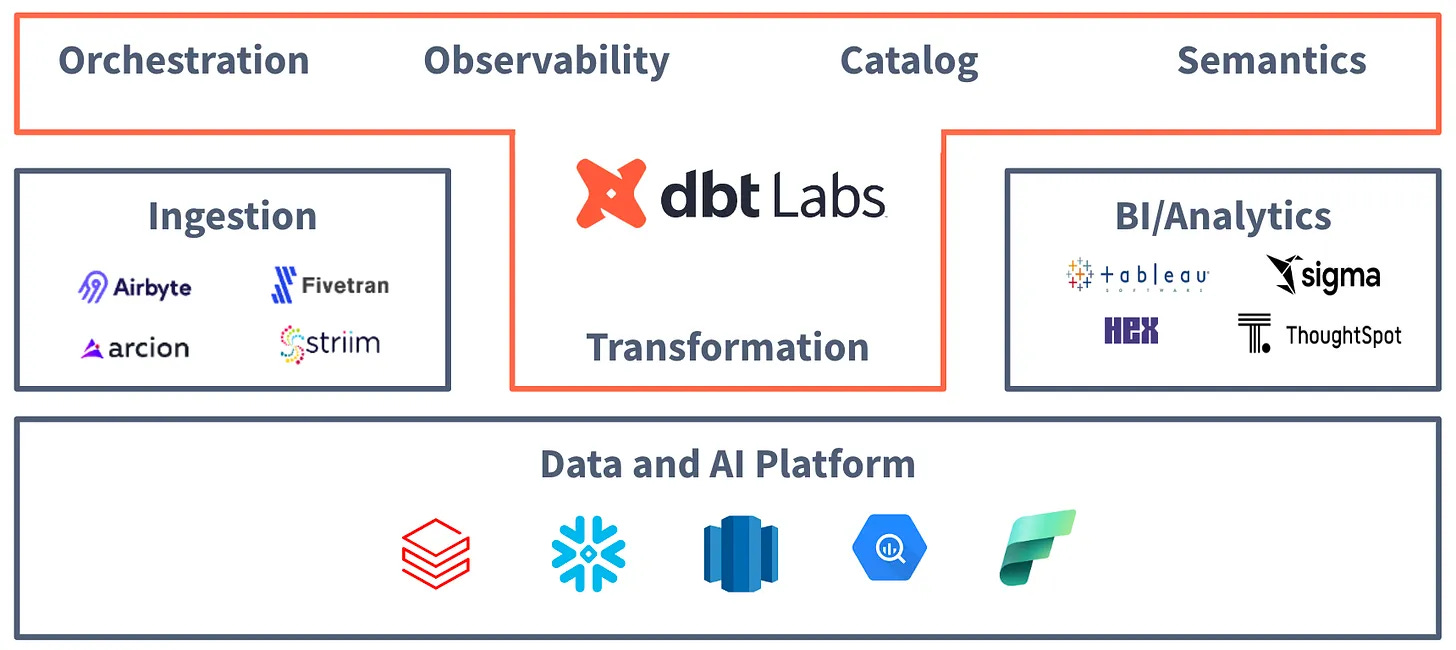
As a business decision, sure. dbt Labs was either going to die a hero or become Alteryx;5 one of those is better for dbt Labs than the other.
But these additions don’t really address the lingering problem in dbt’s core: That none of us really know what we’re doing. That we all improvise a bit too much. That the data modeling program that dbt Labs’ new features will orchestrate, observe, and catalog has been poorly architected, by us, and we don’t know how to fix it.6
Online tutorials, two-day courses, and O’Reilly books won’t teach us how to do it, nor will hand-wringing about the kids these days change today’s kids. Behaviors are shaped by our environment and what that environment lets us do, not the other way around. So long as the big box at the bottom of Slack posts a new message and not a reply, people won’t consistently use threads. If Tesla’s Autopilot Mode lets people zone out when they drive, they won’t be fully attentive drivers, no matter what the warning label says. And if our data modeling programs are going to be efficient and durable, they need to yell at us when we try to write something different.
dbt Mesh could be a start, though it’s more of a set of organizational capabilities than opinions. My suspicion is that dbt needs the latter, and it needs something that aggressively imposes those opinions on its users. It needs dbt on Rails: A framework that builds a project’s scaffolding, and tells us how to expand it—and not through education, but through functional requirements. Show where to put which bits of logic. Prevent me from doing circular things. Blare warnings at me when I use macros incorrectly. Force me to rigorously define “production.”
When I was stumbling my way through building a Django app, I constantly had questions about how to add new things to it, and I had no idea how to fit them into Django’s conventions. Because it’s 2024, I asked ChatGPT for help: “I have a Django app. I want to create a new page where I push a button that fetches data from an external API and displays it on a page. Can you outline how to do this?”
It responds with two things: Sample code, and an outline of how to arrange that code within Django’s organizational framework. The second thing, I found, is actually more useful than the first, because it’s what kept me from turning my app into my Slackbot script. It’s what makes development scalable.
That’s what I want for dbt—either built into dbt Labs, or on top of it, like Django is on Python. I want to ask how I can create a bunch of new financial reporting datasets, and not just be recommended some SQL queries full of commingled logic; I want to be told how to organize all of it too. I want a framework for writing functions on top of my factory for manufacturing tables.7
Everything is BI
We talked last week about Equals, the cloud spreadsheet app that now supports writing SQL. Well. Three weeks ago, as part of their Spring 2024 Product Launch, Sigma—a cloud analytics platform that uses a familiar spreadsheet interface to give business users instant access to explore and get insights from their cloud data warehouse—released a "collaborative environment that makes advanced data science approachable to the business with Python support and a refined SQL experience." Two days ago, as part of their 2024 Spring Release, Hex—a collaborative environment for advanced data analysis that combines Python support and a refined SQL experience—released a spreadsheet interface and no-code data browsing, which “opens up Hex to a whole new universe of people" by giving business users instant access to explore and get insights from their cloud data warehouse.
We are all born with dreams of being different. We have a special collection of features; a new idea; hope. But customer by customer, contract by negotiated contract, we auction ourselves off to the highest bidder. We amputate our extremities first—a small compromise, here and there, for the greater good. Is it not worth selling a kidney to keep ourselves alive? The money is merely a means to advance the mission.
But then we replace a limb, or two, until we finally come for the heart—spreadsheets for notebooks; notebooks for spreadsheets; SQL for analysts; drag-and-drop data visualizations for everyone; whatever you need, just sign the contract. Our bodies, Theseused; our souls, bankrupted, gradually, then suddenly, when we reanimate ourselves under some tagline—the complete cloud solution for business analytics; human-powered AI; the enterprise intelligence suite—as hideously conjoined as the Frankenstein that lurches out of our development laboratory and into some astroturfed Product Hunt post. Meet our new monster, same as the old monster.
We were promised a second coming. We promised a second coming. There were so many companies; so many ideas; so many possible revolutions and reinventions. Surely some revelation was at hand. But no. You can outrun death, but you cannot outrun the devil. The beast approaches, and stalking us into oblivion. We stay different and die, or we survive, dissected and recomposed into an integrated end-to-end analytics workflow.
Favorites
There was also an addendum to Hex’s fundraising announcement: They raised more money from Snowflake Ventures. Two weeks before that, Sigma announced the same thing. And sandwiched in between the two, Omni, yet another BI tool, said that they also raised money from Snowflake Ventures.
Sigma and Hex were both already in Snowflake’s portfolio, and the latest investment in Hex wasn’t (at least publicly) part of a bigger round led by other investors. So these deals aren’t about incubating an ecosystem of promising startups, but, it seems, about Snowflake buying their way onto bigger partners’ roadmaps and boxing out competitors from doing the same. I’ve said before that consolidation doesn’t have to come from outright acquisitions,8 but can come from quid pro quo alliances. That seems like Snowflake’s approach here: In exchange for money and the Snowflake sales team selling Hex and Sigma, the two companies will prioritize building a Snowflake Native App over a Databricks Lakehouse App, or integrate more directly with Snowpark Container Services, or won’t build anything that might dramatically lower how much a customer uses Snowflake. There’s a lot of value as being seen as star around which everyone else resolves, and Snowflake appears intent on keeping other companies in their orbit.
Or who knows, maybe now is just a really good time to invest in software.
And now, a queryable semantic layer.
From Rich Hickey’s famous talk on this subject, simple means the opposite of complex. A straight line is simple; a cursive H is complex. These are objective descriptions. Easy things, by contrast, are near to our abilities. For John Hancock, writing a cursive H was probably easy. It’s a relative description: What is easy for one person might be difficult for another.
SaaS businesses typically hire customer success managers, or CSMs, to make sure customers get what they need from a product, and to sell them new products when they come up for renewal. Being aware of when a customer submitted a feature request or had a technical issue helped CSMs do both.
Photography is a useful analogy here. Back in the day of analog film, people who took a lot of pictures tended to also learn more about the craft of photography. They didn’t have to—the only actual barrier to taking pictures was knowing how to work the camera—but the two got bound together. Why go to the effort of teaching yourself how to use a complex camera and spend money on expensive film if you were going to take bad pictures with it?
Now, the technical parts of photography are much simpler. “Film” is effectively free. That makes photography much more forgiving, but it also means that a lot of people who don’t know anything about how to take good pictures are going to start taking a lot more of them.
dbt’s newer competitors don’t solve this problem either. SQLMesh, for example, is mostly dbt with better developer ergonomics. That’s useful, and might sell well—we all like ergonomic things—but it sidesteps the core issue: How do we become good designers of the thing we’re building?
People, including dbt, tend to measure dbt projects by how many models they have. Which I get; models are the most prominent object in dbt, and are an obvious thing to count. However, that frames dbt in the wrong way. By emphasizing models, we implicitly define dbt as a tool for creating tables. I think it’s more useful to frame dbt as program to create data assets, and dbt models as functions—and we would never count the number of functions in programs. But if we measure in tables, we think in tables.
Notably, Snowflake has a bit of a history of trying to acquire companies it invests in, and the timing of the three announcements, a few days before Snowflake’s annual conference, is at least a little suspicious, if not of an impending acquisition but potentially of some other big show of professional friendship.
I am a pretendgineer (although I like to think I do a good job lol).
The way we work at my company is that a pretendgineer will build something useful (but not "optimized" or "efficient" or whatever) and then once data engineering sees that other people find it valuable, they will formally build a model themselves.
That seems to be a decent way to get over data engineering's hesitancy about taking on projects they don't totally understand and/or see the demand for, while not making the business beholden to convincing a couple people that something is a good idea.
Definitely not a perfect system, but I think it's good to have a bias toward building
Great post as always Benn!
I think you’re exactly right. We don’t have a Django or Ruby on Rails equivalent. We only have a … HTTPServer?
Modeling techniques like DataVault, Kimball, ActivitySchema aren’t it. They online describe the structure of the tables at the start or end of the pipeline. We need something that describes how to organize the code in the middle. And then a library that takes all the boilerplate out of doing it that way.
I hope that a DHH kind of white knight comes along and figures this all out. I’m honestly not holding my breath though - I think data pipelines are just inherently messy and imposing too much structure just doesn’t work. With a web app you’re always going to load your model before rendering a view; with a data pipeline there are no guarantees about the “best” order of operations.
I would love someone to prove me wrong though. The lack of a shared design framework is the #1 reason that large dbt projects invariably regress into shanty towns IMHO.