


In early 2000, Salesforce launched its inaugural product at an event called “The End of Software.” When attendees arrived, they were greeted by a mascot—it was more of a no smoking sign with Mickey Mouse hands and feet than the sort of jolly character you’d see at a college basketball game—that told them they’d arrived in the software-free section of San Francisco. Before taking their seats, guests had to wind through a house of software horrors, full of screaming salespeople.
It was, to say the least, an odd way for a software company to introduce itself. But twenty-one years, $26 billion in annual revenue, and a jumbotron in the San Francisco skyline later, you’d have to say the introduction worked.
It worked so well, in fact, that those of us looking back have a hard time making sense of it. Why would a company have such apparent disdain for the exact thing it’s selling?
In a word, connotations. Before Salesforce’s launch, software—and in particular, enterprise software—wasn’t just a computer program; it was also the frustrating and ugly work necessary to buy and run it.1 At that time, a decade or so into the IT revolution, the promise of what software could be was undercut by what it actually was: a painful buying cycle from enterprise sales teams; a long installation and rollout process; ongoing administration and management; tightrope walks of rolling upgrades. Though IT teams bought perpetual licenses, they still paid a recurring cost of toil and constant trouble.
Salesforce promised something different. They promised software, without the baggage. They promised software that you “didn’t have to touch;” you just sign up and use it.
In other words, the “end of software” wasn’t about getting rid of software; it was about getting rid of the associations people had with it. Salesforce’s ambition wasn’t to provide better answers to common questions like, “what kind of hardware do I need to run this software?” and “what is the cost of upgrading to the new version?” They wanted people to stop asking these questions entirely.
And today, we don’t. Yes, we have plenty of frustrations with software—we have too much of it; it’s eating our world; it’s eating our soul—but many of us barely remember (or never even knew about) the problems Salesforce wanted to solve. Software, as it was understood in 1999, started to end in 2000, just as Salesforce said it would.
The End of BI
The literal definition of business intelligence is vague, but, like software, it’s also taken on a lot of connotations. A BI tool should bring together data from a variety of business sources; it should manage and govern that data so that people can consistently make sense of it; it should make it easy for anyone to self-serve data (whatever that means); it should drive “actionable insights;” it should help companies regularly report on how different business units are performing; it should make dashboards discoverable; there should be graphs.
Many of these connotations were created by early BI tools—tools that were, as software was twenty years ago, heavy and complex. Microstrategy and BusinessObjects, for example, ingested data from a range of data sources into their own storage systems. They each had semantic layers for creating OLAP cubes, transforming raw data into neatly governed datasets. They offered a range of analytical tools for creating reports and dashboards. And they built ways to distribute data around an organization.
Over the last decade, many of these early BI functions have been stripped out of BI and relaunched as independent products. (Add “the unbundling of BI” to the long list of ways that you could define the modern data stack.) Looker, a modern BI tool, doesn’t come with a warehouse and didn’t build data connectors.2 Many customers have replaced parts of Looker’s semantic layer (persistently derived tables, or PDTs) with dbt; other parts could be replaced by a metrics layer. Operational analytics tools take care of distributing data into other systems, and data discovery platforms handle content management. Just as the cloud rewrote our expectations of what software is and what it isn’t, the modern data stack is slowly rewriting our expectations of BI.
But the analogy with Salesforce breaks down in at least one very important way: Once you made it through the maze of software horrors at Salesforce’s launch event, you were presented with a vision for what was coming next. Marc Benioff wasn’t just there to tell you software was dead; he was there to show you how it would be reborn.
In BI’s case, we’ve only done the former. The splinter of the modern data stack that we call BI is diminished, but mostly unchanged. It’s as though we took our definition of BI from twenty years ago and started crossing off clauses, until we’re left with “visualization and reporting.”
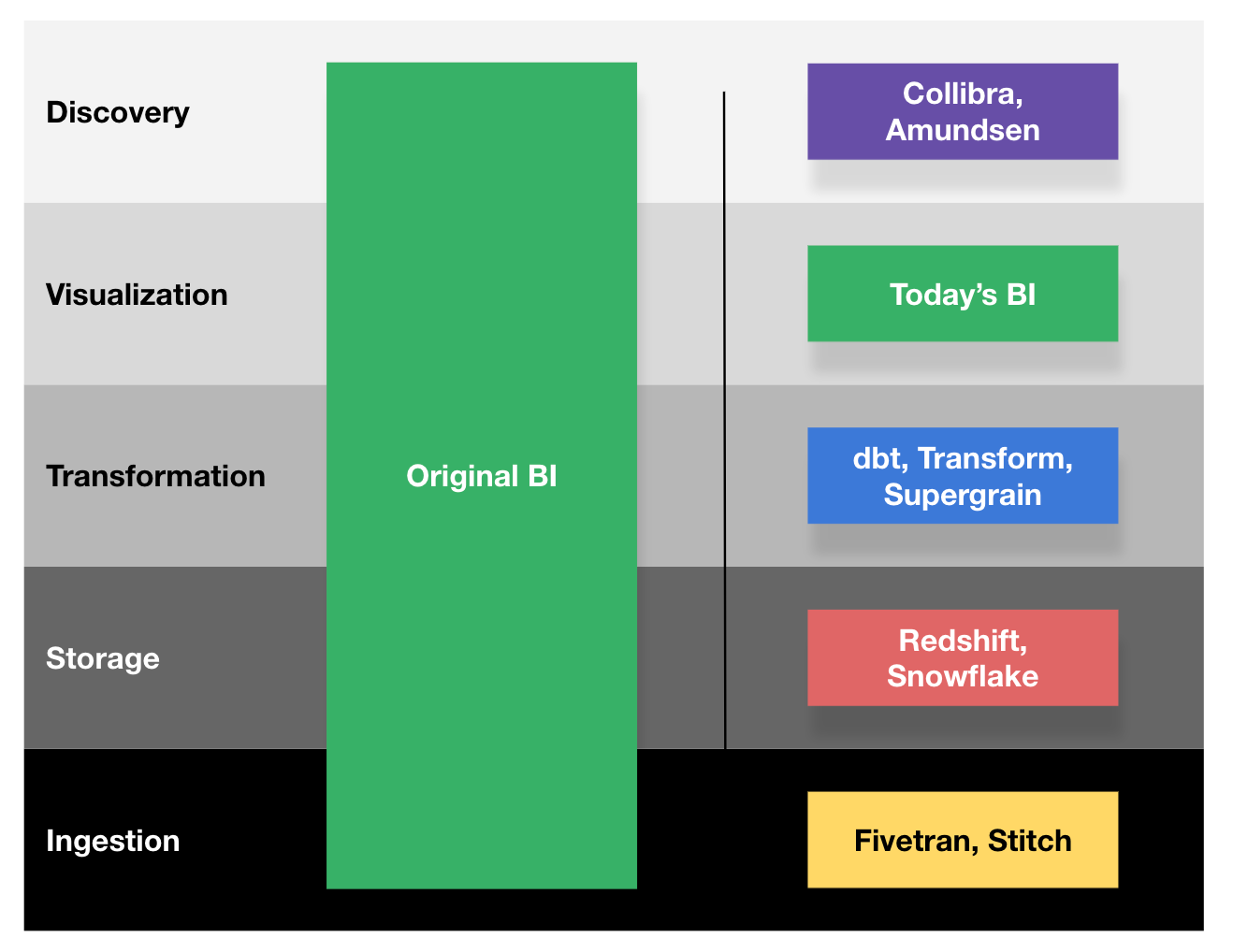
Among the rest of the layers of data stack, it’s an odd anachronism. When we spun off data ingestion, we modernized it: It’s ELT, not ETL. The same is true for warehousing (split storage from compute, among other things), transformation (SQL-based and version controlled, not a GUI), and discovery (automate it based on usage). But our modernization of BI has mostly been ripping it apart, and leaving the remaining fragment unchanged.
If we did change it, what might it be? If we were standing at the end of a labyrinth of BI medusas, what vision would we present? More audaciously, what should our ambition be?3
To play Benioff4 for a minute, BI tools should aspire to do one thing, and do it completely: They should be the universal tool for people to consume and make sense of data. If you—an analyst, an executive, or any person in between—have a question about data, your BI tool should have the answer.
BI should include only consumption
This has a few implications, and while most aren’t controversial—BI shouldn’t handle data ingestion and storage, for instance—two might be.
First, companies use data in operational ways that go beyond people looking at charts. For example, they automate marketing campaigns and build in-product machine learning models. BI should leave these problems to other tools.
That doesn’t mean things shouldn’t happen automatically; if a metric on a dashboard falls below some threshold, absolutely, send an email. But BI tools aren’t pipelines. They’re borders, handing off data between machines and humans. People read data differently than computers—we can digest small amounts of it; we like pictures. We shouldn’t mix what’s meant for humans with what’s meant for machines. And in BI tools, it’s people who do the reading.
Second, BI should be legless.5 As mentioned above, BI tools are just one of several destinations for a company’s data. If BI tools require their own legs—for example, if they rely on a semantic layer to define metrics—they’ll be duplicative, because the same metrics also need to be defined in other destinations. Instead, BI tools should sit on top of global governance layers like dbt and metric stores. Eventually, a semantic layer will be a bug, not a feature.6
BI should include all consumption
Most people consume data in one of two ways: Through a self-serve application, and through ad hoc analyses sent to them by analysts. BI tools traditionally focus on the first channel, and deeper exploratory analysis and data science is done elsewhere. Gleb Mezhanskiy highlighted this divide last year, and it was further emphasized in a recent post from the folks at Hex.
This cracks data consumption in two—and unfortunately, it’s not a clean split. As the Hex post describes, most self-serve reports are built on top of research done in tools built for deeper analysis. Migrating work from the latter to the former—particularly when translating logic from raw SQL and Python into something like LookML—is tedious, error-prone, and sometimes impossible. And when a dashboard surfaces a question it can’t answer, analysts have to traverse the gap again in the opposite direction.
This creates a ton of problems. Ad hoc work is scattered, ungoverned and undiscoverable, outside the organized walls of the traditional BI tool. Self-serve applications take a long time to build, and those that do get built are orphaned from their supporting analyses. Dips in dashboards go unexplored because crossing the chasm from self-serve to analytical tool isn’t worth the effort.7 If a dashboard says one thing and a research report says another—which they inevitably will—it’s hard to know which one to trust.
Moreover, the boundary between BI and analytical research is an artificial one. People don’t sit cleanly on one side or the other, but exist along a spectrum (should a PM, for example, use a self-serve tool or a SQL-based one?). Similarly, analytical assets aren’t just dashboards or research reports; they’re tables, drag-and-drop visualizations, narrative documents, decks, complex dashboards, Python forecasts, interactive apps, and novel and uncategorizable combinations of all of the above.
By defining BI as just self-serve, we shortcut what it could be, no matter how good that self-serve is. A better, more universal BI tool would combine both ad hoc and self-serve workflows, making it easy to hop between different modes of consumption. Deep analysis could be promoted to a dashboard; self-serve tools could unfurl into technical IDEs. This pressure value for complex questions also keeps us from overextending self-serve tools, allowing us to keep them as disciplined libraries for important metrics, rather than unruly tangles of key models and one-off ones.
Even more importantly, marrying BI with the tools used by analysts brings everyone together in a single place. A lot of today’s analytical work isn’t actually that collaborative: People uncover something interesting in their BI tool, and ask the data team about it when they can’t self-serve an answer. Analysts squirrel their work away in technical tools, and results are ejected from those tools back into the business. Non-analysts motivate the analytical process, but aren’t part of it directly.
Gathering everyone in one place fixes this experience. It tightens collaborative loops, not only between analysts and non-analysts, but also among non-analysts. This cross-side collaboration—to borrow from Kevin Kwok’s excellent discussion of how Figma enables the same thing in design—helps companies finally escape the analysis-as-a-service model by making data larger than just data teams.
BI is dead, long live BI
The professional software referees at Gartner evaluate BI tools across a number of “critical capability areas,” including connectivity, data preparation, cataloging, reporting, and visualization. Just as we no longer ask what kind of hardware is required to run our CRM software, this battery of features represents an outdated notion of BI.
Future BI tools should be judged by a different set of questions. Does it adhere to modern analytical conventions? Does it support familiar languages and frameworks, or proprietary ones? Does it require its own semantic layer, or can it integrate with other governance tools? Can a range of data consumers, from data scientists to CEOs, use it to create a range of data assets, from dashboards to deep research reports? How hard is it to migrate from one type of asset to another? Does it help analysts and non-analysts collaborate between and among one another? Can it be a universal tool for data consumption?
So long as companies need dashboards and executives need reports to go spelunking through as they wait for the economy class passengers to board, we’ll need BI. But the old version of BI—a complete end-to-end stack, responsible for nearly all of a company’s analytical needs—is already dead. The question is what replaces it.
“Commercial air travel” is similar. Though this phrase literally means paying money to fly, it conjures all sorts of nightmares of delayed flights, cramped planes, nickel-and-dimed amenities, lost bags, and, of course, monstrous passengers.
Though it seems like their new Google overlords might.
At this point, you may be asking if this is my opinion, or Mode’s? The answer is mine; this Substack doesn’t represent Mode’s official stance on anything, and certainly shouldn’t be read as any sort of roadmap. But, I do have a fair amount of influence over what Mode does, and my experience at Mode has a great deal of influence over what I think. So, Mode’s vision is directionally similar to what follows, though the specifics vary.
More like BENNioff, amirite? (You can unsubscribe at https://benn.substack.com/account.)
Earlier this year, Ankur Goyal and Alana Anderson introduced the term “headless BI.” This is very similar to (and preceded) my proposal for a metrics layer, and I very much support the idea. However, I think the term is backwards. To me, BI is consumption. If it’s headless—i.e., if it requires another tool to consume—it’s not BI. To put it another way, if you split Looker into LookML and a visualization tool, which one would be BI?
Yes, fine, you could argue that, technically, anything that prepares data inside an analytics tool is a semantic layer. A query is a semantic layer! An Excel formula is a semantic layer! A chart configuration is a semantic layer! I’m not referring to these sorts of layers, but to those that are intended to be central repositories of governance, and are described as a “single source of truth.”
When the grocery store is far away, we forget how to cook. –Not a proverb, but should be.
just read your other post on Minerva. I agree with your preference for SQL over API.
Regarding YAML - I am not sure that YAML is expressive enough to compute metrics. What we did on the flaskdata.io metrics layer was to wrap SQL inside functions with a standard calling convention in order to compute the metrics from the time series data. I won't pretend that its ideal - the debug process is not pleasant but once it works, the job is done.
To get some more flexibility we use YAML to define how to extract the actual metrics into the BI
borrowing a page out of transform's play book.
For our next product, I'm serious considering OpenTelemetry
Given that computation of metrics is usually not part of the data access layer; it seems to me that metrics is a layer unto itself. This enables us to hide the computational complexity of deriving metrics from time-series data from the BI. It also enables a design where we can compute and expose live metrics from inside the operational process (as is commonly done with operating systems). I believe that this makes sense in particular when you have a slow moving process (like clinical trial data).