LLMs shouldn’t write SQL
There's no direct path from a business question to a useful query.

There are, very roughly, two ways to analyze data:1
[ People can ] work like journalists, collating existing metrics and drawing conclusions by considering them in their totality. Rather than looking for new ways to assess a question, they start by asking, “how do we currently measure that?” [ Or they can ] work like scientists, creating new datasets and aggregating them in novel ways to draw conclusions about specific, nuanced hypotheses.
In business contexts, the first type of analysis typically consists of asking a series of Mad Lib-style questions about known metrics, like revenue retention or daily active users or ad spend, and aggregating and filtering those metrics by different dimensions. “Show me total orders in Massachusetts by month compared to the same number from a year ago,” someone might ask. This question will reveal something, like a spike in new orders in February. And that will prompt more questions of the same style—“now show me total orders in Massachusetts by month and by product category”—until people find whatever they’re looking for.
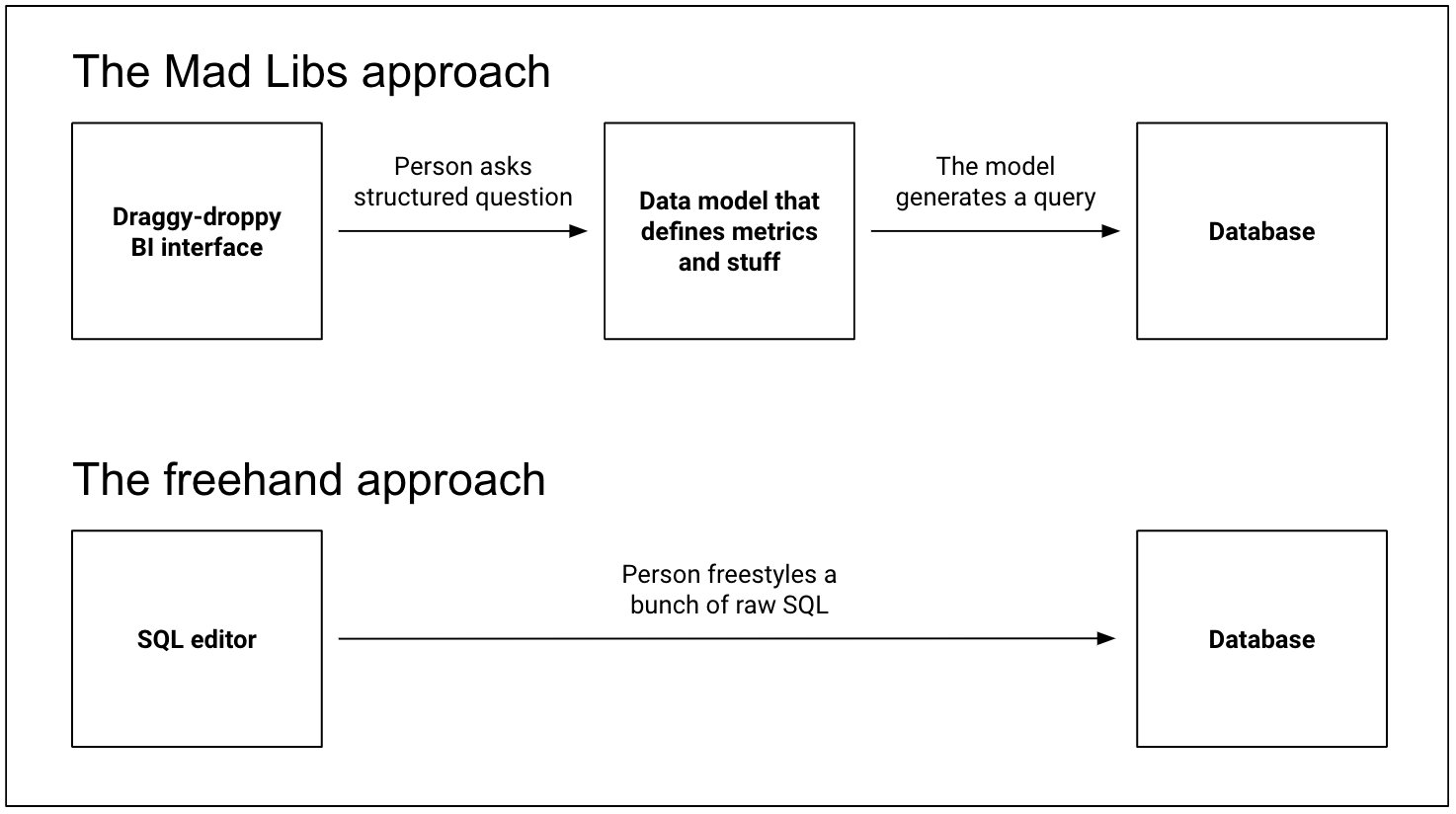
These questions are often answered using BI tools. Most BI tools support this with more or less the same architecture. First, there’s some sort of data model in which people define metrics, how they should be calculated, and the ways they can be aggregated, filtered, and combined. And second, there’s an interface where people choose which metrics they want to see and how they want to aggregate, filter, and combine them. The former defines the structure of Mad Lib sentences and the words that people can choose to fill them in; the latter lets people fill them in and gives them tables and charts of their results.2
Though people can be combinatorially creative in how they complete their sentences, this approach puts guardrails around the sorts of questions that they can ask. You can’t fully improvise in a BI tool, and that’s the point—to let people ask questions, but make sure that whenever they make a chart of their company’s revenue, they’re using the correct formula for calculating it.
The second method of analysis is less structured. It usually starts with a looser question—“was our Super Bowl commercial worth it?”—that can’t easily be answered with off-the-shelf metrics. Historically, these questions are answered by analysts who collect and clean new datasets and aggregate them up in some bespoke way. It’s unlikely, for example, that Dunkin’ Donuts’ has any canonized KPIs on orange jumpsuit sales in their BI tool; instead, somewhere at Dunkin’ HQ, there’s probably an analyst who’s trying to braid together a bunch data on social media impressions, website visits, and donut sales in SF and Kansas City, not to create a dashboard, but to help the Dunkin’ CEO explain to his private equity overlords why the Bennifer reboot was worth $30 million.3 Because these questions require a lot of analytical offroading, they’re commonly answered using unstructured tools like Excel, or using open-ended languages like SQL and Python.
Of course, this divide isn’t perfect; there are times when people use both approaches, and there are tools that try to offer hybrid solutions. But the split broadly works: Some analysis is done using code-free interfaces that generate SQL for you, and some analysis is done by people writing custom queries from scratch. Or, if you prefer a boxes and arrows:
Last month, Gartner predicted that all of this is going to change? I think?
By 2025, use of natural language as a primary data management API will be the dominant interface leading to a 100x consumption of data across the ecosystem. …
Natural language will replace SQL as the dominant query interface expanding access and use.
Well. As a vague prediction, sure—AI will save humanity; it is the most transformative invention since the printing press; Nvidia is bigger than Google; Nvidia is bigger than the American banking industry;4 Nvidia is bigger than Spain; etc, etc, etc. If AI is going to eat the world, it'll probably eat SQL too.
But how? This is where things seem more complicated, and SQL—ever the technical zombie, always dying but never dead—seems more durable.
One possible answer is that natural language becomes the new interface for BI. Rather than dragging and dropping pills into drop zones, people could write their analytical Mad Libs—“compare total sales by month in Boston and Charlotte for the ‘Fenway faithful’ and ‘Go Hornets’ donuts”—as sentences. For many people, this would be much more accessible than the complex and crowded interfaces that most BI tools have today.5
But! If this is how we use natural language to answer questions, it doesn’t replace SQL. In fact, these chatbots probably won’t even write SQL. Early product development efforts, research papers, and a handful of informal studies have consistently found that, even when asking these structured Mad Lib-style questions, LLMs don’t write particularly reliable SQL on their own6—but they can figure out how to configure a BI tool based on a natural language question. Moreover, having the LLM sit on top of a data model, rather than outright replace it, protects against wild hallucinations, because the LLM is bound by the same guardrails that protect BI tools’ human users.
Put differently, if natural language is used for solving the first type of analytical problem, it will likely do so by putting a “natural language chatbot” box to the left of the BI box in the diagram above. People will ask it their questions; some LLM fine-tuned on schema documentation and business jargon will figure out how to express that question not as a query but as a series of inputs into a BI tool; the BI tool will generate the query.7 There’s no reason for the LLM to ever write a query directly.
That would make the Gartner prediction kind of weird? SQL would serve the same role in this world as it does in today’s; the LLM just updates how we generate that SQL.
Which leads to the second way to interpret Gartner’s prediction—that LLMs replace the second way people do analysis. Natural language won’t just help people ask structured questions; it will also be the chosen way people do complex analysis too. It will, as Gartner says, “replace SQL as the dominant query interface.” Could AI do that?
Today, no? But a huge number of companies are building AI agents that turn questions into SQL queries. They are all doing lots of work figuring out how to write good queries; context-aware queries; queries trained on your data, on your documentation, on other SQL queries. And the consensus view seems to be that, eventually, because of this work and the unrelenting advancements in AI, LLMs will be able to write infinitely complex queries based on English prompts.
But, with all the focus on figuring out if we can do this, we seem to be ignoring a more important question—do we want to?
Suppose you need to draw an owl. Today, with generative AI, it’s easy—just open up DALL-E or Midjourney or whatever new startup launched a stylized wrapper around DALL-E or Midjourney this week, and say, “draw an owl.” Seconds later, you’ve got an owl.
{kind=link}
Now suppose you need to draw the owl at the top of this post. You're in the woods without a camera, and a baby owl, that baby owl, lands on a branch next to you and mugs at you with every ounce of outrage that it can muster. Amazing, you think; other people must see the owl. But you can’t just show them a generic owl, or some imperfect tribute to your owl; they must see this owl, exactly as you see it, in all of its adorable, indignant splendor.
You could do this with AI too, but it would be really hard. I couldn’t get close at all:
{kind=link}
Draw an owl. It should be a baby owl. It's perched on a green mossy branch that should be barely visible in the lower left corner of the picture. The baby owl's body is facing slightly to our right, and its head is turned facing directly towards us. It's got a mix of brown and white feathers. Its eyes look angry, but the feathers underneath its beak are turned up slightly and look like a smile. The baby owl is in the foreground of the picture, and should be positioned in the left two-thirds of the frame. The background behind the baby owl is in the right third of the frame, and is mostly green and brown. We can't tell what is behind the owl because it's out of focus, but it's probably the woods. It is adorable.
The problem with drawing an owl like this is that the axiom that “a picture is worth a thousand words” has a corollary: It takes a thousand words to describe a picture. And even that’s probably an understatement—Nathaniel Hawthorne8 could fill a book with words about that owl, and I doubt even he could ever get ChatGPT to recreate it.9
But AI could help me draw that owl in other ways. I could sketch the owl by hand, give my picture to ChatGPT, and ask it to make my drawing better, based on some English descriptions of the parts I couldn’t draw myself. I could upload pictures of other owls that look like that owl, and tell the bot how to use those pictures to improve its drawing. I could use a UI-based photo-editing tools, like Photoshop’s Generative Fill and Google’s Magic Eraser, that let me directly modify the picture ChatGPT produces without having to be terribly precise with my edits. Though I still wouldn’t be able to recreate an exact replica of that owl, I could get a lot closer using these inputs than I could with English alone.
The obvious point here is that natural language isn’t always a particularly useful way to create something. For certain types of output, English is crude, imprecise, and painfully inefficient.
Now, instead of needing to drawing an owl, suppose you needed to write a formula in Excel that classifies a company into market segments by employee count:10
=IFS(A1>=1000,"Enterprise",
A1>=250, "Midmarket",
A1>=1, "SMB",
TRUE, "Unknown")ChatGPT can kinda do this. Asked to “write an Excel formula that categorizes cell A1, which contains the number of employees at a company, into one of three segments: Enterprise, Midmarket, and SMB,” it produces this:
=IF(A1<=100, "SMB", IF(A1<=1000, "Midmarket", "Enterprise"))It’s close, but gets all the details wrong. It draws the line between SMB and Midmarket at 100 employees instead of 250; it rounds down, putting companies on the threshold between two segments in the smaller one instead of the larger one; it doesn’t handle cases when employee counts are zero, negative, or unknown. Though these issues are all fixable, it takes more than 300 characters to explain them, compared to the 75 characters in the original Excel formula. And despite its length, the formula is also more precise—the English prompt doesn’t specify what should happen if A1 is a non-numeric value.
Even for this tiny example, we can start to see the problem with doing analysis with natural language. There are thousands of computational devils in details like how to handle nulls. For analysts, describing these specifics in English is inefficient and inexact. For everyone else, they wouldn’t know they need to describe them at all.
To draw a baby owl, I don’t want to describe it, adjective by adjective; I want to crudely sketch it, and use AI to forgive my unsteady hand. To create a numbered list in a Google Doc, I don’t want to open an AI wizard, and type “list,” and have it say “It looks like you want to create a list of things! I can help with that. Would you like a bulleted list or a numbered list?,” and then type “number;” I want to push a button or use a hotkey. And I don’t want to describe, in anemic, gingerbread English, the precise and complex series of joins and functions that I need to perform to create a one-off measure of brand engagement around a sixty-second Super Bowl spot. I want to write code. Sort of.
The precision and compactness of code comes with a tradeoff: It’s tedious to write. There are small things that are annoying to do, and computers are finicky with details, like forgotten parentheses and misplaced commas. When analysts write SQL queries (and probably when an engineer writes code, but their dark arts remain a mystery to me), part of the work is staring blankly at the ceiling, trying to figure out what you want to do, and part of the work is writing actual queries that do the thing you want. And the second part is constrained by the tedium of remembering how functions work, and typing out long case statements, and trying to figure out how to do some stats thing that you know how to do in R but don’t know how to do in SQL.
Ideally, analysts wouldn’t have to do any of this. Ideally, they could write something akin to pseudocode. Sketch the structure; hand-wave past the syntactic details.
If AI is going to help with the second type of analysis, this is how I hope it does it—not by answering English questions, or even by authoring entire queries from a single prompt, but by letting me mash up poorly-written SQL and English in one mixed medium sketch. Like how I want to use a bad drawing of an owl to create a good one, I want to use a bad query to help me write a good query. Let me be precise about the details that matter, outline the ones that don’t, and ask the big-brained supercomputer figure out it all fits together.11
In other words, LLMs as a better interface to data models and semantic layers are great. LLMs as a Eucharistic for transubstantiating sketches of queries into real ones are great. But LLMs as an analyst, turning novel business questions into full queries? Seems unwise.
Modern data blowback
The investigation into whether or not the modern data stack is dead or alive continues. After Tristan shivved it two weeks ago—“Et tu, dbt?”—others have weighed in, declaring it some mix of dead, alive, or in need of being reanimated under a new brand.
Before we tire of this debate too much, I have one more comment. In his post about the topic, Christophe Blefari12 pointed out that we seem to be getting hung up on the name, and particularly the “modern” part. Should we move on from the term, so that we’re can stop pretending that something that’s ten years old is still new?
Like, no? At this point, the phrase is useful as a historical marker, and as a label for the data industry’s recent boom and bust cycle. It’s our dot-com era, or Web 2.0, or Web3 (or, even more analogously, our modern art era). It’s not a literal description of how new something is, or of the version of the world wide web we’re using; it’s an epochal delimiter. And in that sense, it’s a very useful shorthand.
The interesting question, then, isn’t if we should retire the term; it’s if we should retire the prevailing philosophies associated with the term.
I think the early verdict is, kinda? Of my four major tenets of the modern data stack, we should probably keep a few and ditch at least one:
Copy engineering best practices. This one—defining more things in code, use version control—seems like a winner. Though I know people who miss elements of Informatica and SnapLogic, I don’t know anyone who’s eager to use their opaque GUIs to manage their data pipelines.
The cloud. Also a winner. Yes, the cloud has its critics, but it would take a titanic technological shift to reverse its momentum at this point.
SQL. A bit of a mixed bag? One one hand, it reincarnated itself after the early 2010s experiment with Hadoop, so it’d be foolish to bet against it. On the other hand, there are three certainties in life: Death, taxes, and that someone is launching a new project to make a better version of SQL. It’s the ultimate technical cockroach—somehow both perfectly designed and disgusting at the same time.
Modularity. This, to me, was the modern data stack’s colossal miss. The ambition was noble enough, but the economics never worked and the experience was dysfunctional. Worse still, the belief in modularity helped inflate the bubble, by convincing people—and VCs—that there was space in the market for every specialized wedge.
Undoubtedly, as the bubble bursts, as everyone moves on to AI, and as people get bored with the old thing, some new set of philosophies will replace these. And some clever marketer will brand it with a new term. Which, sure, great, let’s do it. But I’d argue that the modern data stack has a well-understood descriptivist meaning at this point; no reason to muddy those relatively clarified waters.
Some personal-ish news
Last week, I shared Anu Atluru’s theory of Type I and Type II entrepreneurs:
There are those in it for the love of the mission that they’re obsessed with championing. And there are those in it for the love of the game of entrepreneurship itself, almost irrespective of the mission of the business. Sometimes the mission is the business and sometimes the business is the mission. Type I, and Type II.
There's probably a parallel version of this theory for politicians. Some people run for office because their mission is ambition and success; some people’s ambition is the success of their mission. Unfortunately for all of us, most politicians seem to be in the first category, willing to sell their beliefs for the sake of their careers.
My brother—some of you may know him, from his very prominent presence on Twitter—is the most firm member of the second category that I know. He has strong opinions, genuinely held, and will fight relentlessly for them, regardless of who they offend or how little they help him personally. Say what you will about his particular political beliefs, he’s the sort of person that we need more of in politics.
This week, he announced that he’s running for a seat in the Minnesota House of Representatives. It’s a small campaign, and every contribution to it helps. If you believe in what he believes in—and if you want fewer people in politics fighting for their careers and more people fighting for a mission—become a supporter.
I flipped the order of this quote. Please don’t tell Bill Ackman.
In Looker, LookML is the former; Explores are the latter. ThoughtSpot has worksheets for the former and search for the latter. PowerBI has a data modeling tool and a visualization builder; Tableau has a data modeling tool and a visualization builder; Qlik has a data modeling tool and a visualization builder. It’s all structurally the same thing; the differences are in how you make the model and how you interact with it once you make it.
If you are this analyst, wow I would love to talk to you.
For example, to compare donut sales between Boston and Charlotte in Tableau, you have to 1) know which datasets have regional sales, 2) know how to navigate to that dataset, 3) know which field—often from a list of dozens or hundreds, including things like “sales,” “net sales,” “revenue,” and “purchase amount”—is the right one for measuring total sales, 4) know which field contains details on the donut type, 5) know the exact name of the two types of donuts, and 6) know how to configure the Tableau visualization to show monthly sales by region and product type, and 7) know how to create a custom calculation that compares one city’s sales with the other. There’s not much code, but there’s a learning curve.
It’s worth noting that all of these studies came from companies that would prefer for LLMs to work this way.
I mean, no, that’s not quite right. LLMs don’t interact with the BI tool’s user interface directly; they instead write code that calls the BI tool’s data model via API. So, more precisely, the chatbot box should replace the draggy-droppy box. But, same idea.
I’m evidently still scarred from having to read The Scarlet Letter in tenth grade, and Hawthorne spending the first fifty (fifty! fifty!) pages describing a customs house.
But maybe you can??? Send me your attempts! The person who is the closest gets a pair of Apple Airpod Pros, unless you don’t, or your owl is wrong; in that case, the people who sent other owls get a $50 DoorDash gift card, as long as their owls are first, and better owls are after your owl. Otherwise, the first owl wins, assuming there are other owls, and all owls remain qualified. It’s a win-win!
Formatted for legibility. Obviously, if this were a real formula in a real Excel workbook, this would be on one enormous, hideous line.
Both Mode and Hex—both of which are productivity tools for analysts—take roughly this approach. I think that’s right, but I would say that.
People periodically ask me how I keep up with industry news. The honest answer is I don’t. The useful answer is that I read Christophe’s newsletter. As news digests go, it’s the best one out there. It’s comprehensive but not overbearing; Christophe’s commentary is unflinching but not bombastic; it features a good mix of both technical news for real practitioners and industry gossip for paparazzi like me; and it’s written from the view in Paris, so it isn’t infected with Silicon Valley’s exhausting main character energy. Whereas newsletters like this one are newsletter in form but self-satisfied and self-serving soapboxes in function, the Data News is pure. It’s good stuff, go sign up.
I like how the English speaking world came up with Legalese because English is so ambiguous, and now a whole bunch of people pretend that they can program computers with natural language. 😅
After reading the first half of this I was going to make the point that humans who had “natural language” at their disposal choose to use SQL instead of natural language to interact with data…. But you pretty much made that point already.
Secondly - everyone think back to your analyst days… When is the last time you got a coherent English paragraph as a request for an analysis/dashboard/report? Mine were always the results of a hand waving conversations with torn off sheets from yellow legal pads with unreadable diagrams and handwriting. So if AI can deal with that - sounds awesome!