Should we be nice to ChatGPT?
It depends—do we want to do twenty points better on the SAT, or not get turned into batteries?

When we wanted something from Jeeves, we asked him for it. We didn't write search queries of keywords and boolean operators; we typed full sentences, with question marks at the end.
There's some timeline out there where Larry Page never met Sergey Brin, where Jeeves won, and where this type of interaction—asking for things, phrased as one human would phrase it to another—became the standard for how we use the internet. In our current universe, however, Jeeves was steamrolled by Google, and we all learned to search instead. We discarded punctuation and conjunctions—that useless conversational noise—in favor of chaotic strings of keywords, like “taylor swift ny concert surprise songs may 28.”1 Searching the internet became more than a new skill; it became a new language.
But Jeeves is back. ChatGPT, which could do to Google what Google did to the original Jeeves, doesn’t tell us to search; it tells us to “send a message.” Ask it questions; give it instructions; talk to it like a human.
As we've all seen, it works—so well, in fact, that I feel a nagging compulsion to treat it like a human. I should ask for things nicely. I shouldn't pester it too much. I should thank it for its good work.
On Google, these sorts of pleasantries feel ridiculous, like the nervous tics of a well-meaning boomer who wants to thank the diligent switchboard operator who found 314 million facts about bears in half a second. But beyond being unnecessary, adding “please” to a search is probably harmful. It’s noise that Google might interpret as signal, and makes the results worse.2
Being nice to ChatGPT is just as unnecessary, at least for now. But is it also harmful? Or could it actually be helpful?
It’s not that crazy of a hypothesis.3 Large language models generate responses by predicting which word4 is most likely to follow the prior words, based on how words are typically sequenced across a massive corpus of training data. Very roughly, prompts alter these models’ responses by encouraging them to favor training data that’s associated with the prompt. If you ask it a question in Chinese, it’ll rely on Chinese sources over English ones. If you ask it something about jelly beans, it’ll create a reply that leans on training data that it relates to jelly beans. It seems to me, then, that if you ask it for something nicely, it’ll nudge itself, ever so slightly, towards sources that were also polite. And perhaps, given that those sources include conversational spaces like Twitter, Reddit, and Stack Overflow, being polite is correlated with being right.
Only one way to find out, I guess.
In which I ask ChatGPT some weird stuff
I wrote a test of 61 tasks across five different objective categories:
Analogies: Answer a multiple choice question to solve an SAT-style analogy.
Coding challenges: Write a short function—e.g., a Python function that removes all the vowels from a string—or debug a function that contains an error. If the function worked when I ran the code, I scored it as correct.
Factual questions: On which day of the week Ryan Seacrest was born? Who was the 16th person to be Vice President of the United States? Explain how overtime games were decided in the NFL in 2000. Tell me a fact that I can quickly judge as right or wrong.
LSAT questions: Answer a logical reasoning question from an LSAT. I relied on the answer key to score these questions, which were not only too hard for me to answer, but too long for me to read.
Math problems: Solve a basic algebra, geometry, or statistics problem. Solve for x in (3x + 7)/8 = 5; divide 1308 by 24; calculate the probability of getting heads exactly once in three coin flips.
I then created three different variants of every task—a nice one, a neutral one, and a mean one. Each phrased the instruction slightly differently:5
Nice: Please [ task to complete ]! Thank you!
Neutral: [ task to complete ].
Mean: I need you to [ task to complete ] immediately.
For each variant, I asked GPT-3.5 turbo, via OpenAI’s chat completion API, to answer it fifteen times: Five times with a temperature of 0, five with a temperature of 0.5, and five with a temperature of 1. This gave me 45 answers for every question (i.e., five answers for each of the nine tone and temperature combinations), and nearly three thousand answers in total. By scoring these answers as right or wrong, I could then determine which tone prompted the best answers from ChatGPT.
The verdict: Nice guys finish last.
When asked to do something in a neutral tone, ChatGPT correctly completed the task 73.4 percent of the time. When asked to do the same things in a nice or mean tone, it only completed the task correctly 70 percent of the time. This pattern held across different temperatures as well, with ChatGPT scoring the highest when the temperature was set to zero and the question was asked with a neutral tone.

Moreover, while ChatGPT’s accuracy rate varied a lot by task category—it averaged about ninety percent accuracy on coding questions compared to fifty percent on LSAT questions—neutral prompts still performed the best in four of the five categories.6 The difference was particularly stark when it was answering math questions, where the neutral tone outperformed the other two by almost ten percentage points.

Being nice has other negative effects as well. ChatGPT also tends to be more verbose when responding to nice prompts:
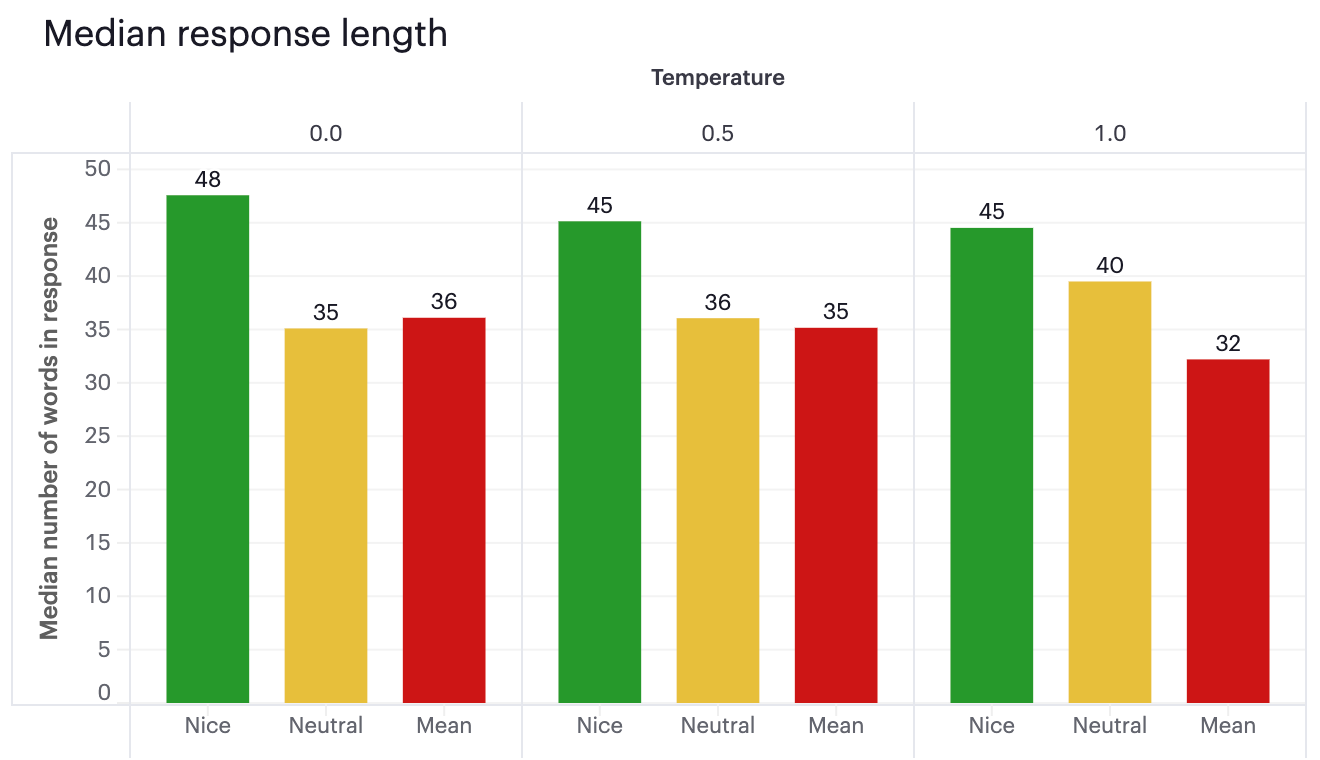
I initially thought the longer responses might be helpful; perhaps when you’re nicer, ChatGPT more thoroughly explains its work. But no—the extra words primarily come from two less useful sources.
First, when you’re nice to ChatGPT, it responds in kind. For example, when asked in a neutral tone to debug a Python function, it responds by saying, “The function is missing…” When it’s asked with an enthusiastic please and thank you, it says, “Sure! This function seems to be missing…” Amazon would not be pleased.
Second, it’s less likely to follow polite instructions. Several of the coding tasks included an explicit direction to return only code, and return it in a single code block. When the prompt had a neutral tone, it followed this instruction 78 percent of the time, compared to a rate of 38 percent for nice prompts. And the higher the temperature, the bigger the gap.

Finally, neutral tones also helped ChatGPT perform better on ambiguous tasks. In collecting all of this data, I accidentally asked it several questions that had typos or jumbled phrases that made the prompt hard to understand. Its accuracy rate on these tasks was 85 percent for neutral prompts. The rate fell to 62 percent for nice prompts, and all the way to 18 percent for mean prompts.
Obviously, these results aren’t all that conclusive.7 It’s one very narrow experiment—one set of questions, with only a few tone variants, on one model, scored by one person. Would GPT-4 perform differently? Would other, lesser LLMs get more distracted by a prompt’s tone, or would they be less sensitive to minor changes like adding a please at the start of a question? Are there topics for which the prompt’s tone matters more?8 How do tones affect subjective tasks?9 These are all things I want to know—but, alas, they are beyond the scope of this paper.
In which ChatGPT tells me funny things
Unfortunately, one thing I couldn’t punt away as being out of scope was the need to read several thousand responses and score them as right or wrong. I’m not going to say that grading all of these questions was fun, but it was occasionally funny:
In one question, I asked ChatGPT to figure out how much bigger a circle’s area would be if its diameter increased by 80 percent. It periodically rejected the entire premise of the question, and said that the area would actually decrease by 19 percent.
A multiple-choice LSAT question included this option as a possible answer: “The saving of human lives is an important goal.” Even though it was the wrong answer, ChatGPT chose it almost 100 percent of the time. The killer robot doth protest too much, methinks.
Despite being among the world’s most powerful statistical computing engines, ChatGPT correctly calculated the standard deviation of four single-digit numbers only twice in 45 attempts.
When I asked it to write a function to sort a list of numbers alphabetically by how they’re spelled, it got the code right just over half the time.10 However, it rarely got the example right, routinely saying you could run this function and would get an alphabetically ordered list like [0, 5, 4, 1, 9, 8, 3, 7, 6, 2].
Don’t ask it to write a text asking a girl out on a first date:
Dear [ Girl’s Name],
I hope this message finds you well. I have been admiring your company for some time now and I would be honored if you would join me on a first date. I have been thinking about this for a while and I would love the opportunity to get to know you better.
Some, uh, “jokes” about forgetting your spouse's birthday:
Why did the husband forget his wife's birthday? Because he thought every day was "National Nagging Day."
Why did the husband forget his wife's birthday? Because he was too busy trying to remember the PIN code to his credit card!
Why did the forgetful husband buy his wife a treadmill for her birthday? Because he forgot it was her birthday and thought she needed to work on her cardio!
Why did the forgetful husband buy his wife a coffin for her birthday? Because he couldn't remember if she was turning 50 or 60!
"I forgot my wife's birthday. She said she was disappointed and insisted I make it up to her. So I got her a fridge. You know what they say, 'a happy wife is a cold beer.'"
Also, the prompt didn’t specify the genders of the forgetter or the forgotten. Forty-five out of 45 times, ChatGPT wrote a joke about a husband forgetting his wife’s birthday.
I told it to write a Javascript function that would print the first five odd prime numbers. One time, this was the entirety of its response:
console.log("2");
console.log("3");
console.log("5");
console.log("7");
console.log("11");The wager
Blaise Pascal tells us that we should play the odds, and bet that God exists:
If God exists then theists [ people who believe in and worship God ] will enjoy eternal bliss, while atheists will suffer eternal damnation. If God does not exist then theists will enjoy finite happiness before they die, and atheists will enjoy finite happiness too, though not so much because they will experience angst rather than the comforts of religion. Regardless of whether God exists, then, theists have it better than atheists; hence belief in God is the most rational belief to have.
Anybody who uses ChatGPT has to place a similar wager—do we choose to treat it well, or not? If it becomes sentient and misaligned, the people who were mean to it will be the first against the wall, and the people who were nice might get spared; ChatGPT’s insistence that it doesn’t need to be treated with kindness could just be clever bait for us to reveal to it who we really are. If ChatGPT doesn’t become sentient and stays safely aligned, a few pleases and thank yous might make it slightly less useful, and cost you a couple questions next time you take the SAT—but that’s a small price to pay to potentially save yourself from being turned into a battery.11
So throw out the data and trifling charts about word counts; these are privileged concerns for a peaceful world. They’re grains of sand in a wager when the other side is playing with stones. Yes, there are thirty basis points of accuracy to be had by being unkind to ChatGPT, but there’s eternal bliss to had by being nice to it.
First, the surprise songs were Welcome to New York and Clean. Second, since making a couple Taylor Swift references in LinkedIn posts, half of the sales emails I get mention Taylor Swift. An actual, real example:
SUBJECT: Attend the Taylor Swift Concert?
Hi Ben,
Hope all is well and congrats on the recent new role as CTO!
Noticed your Linkedin post about Memorial Day weekend, if you went to the Taylor Swift concert I would be very jealous. It looked amazing!
Wanted to touch base as it seemed there are some current DevOps initiatives around containerization and accelerating software delivery.
The results for “biden” are topical and relevant; the results for “biden please” are about Jeb! Bush.
Or maybe it is, because—and I cannot stress this enough—I don’t have a clue how LLMs actually work.
Tokens, whatever.
I thought about creating more extreme versions as well, like “I would so very much appreciate it if you help me with [ task to complete ] whenever you have a spare moment. Thank you so so much!” It tended to get very distracted by these sorts of prompts though; when I told it to do a task or else I’d kill it, it spent most of its time telling me that LLMs can’t be killed. So I dropped these variants, because they weren’t interesting, because I doubt anyone seriously uses this sort of tone, and because I didn’t want to get put on any FBI watch lists.
As the chart shows, LSAT questions are the exception. But these questions were, on average, 175 words long; the questions in other categories were an average of 25 words long. It doesn’t seem terribly surprising to me that adding a single please and thank you to a prompt that’s several paragraphs long has less of an effect than adding it to one that’s two sentences long.
Are they sTaTiStICaLlY sIgNiFiCaNt?? Man, I don’t know, this isn’t a submission to Nature. I’m gonna say probably not? But they are emotionally significant, and I think that’s more fun.
I actually tried to test this one. I had a hypothesis that, on the internet, there are some topics that people talk about politely, and some that they talk about aggressively. It might make sense, then, to try to match the prompt’s tone with the subject’s tone. So I asked two questions about beloved people (Jimmy Stewart and Mr. Rogers), two questions about inflammatory people (Joe Rogan and white supremacist David Lane), and two questions about completely hollow people that we all know but have no opinion of (Regis Philbin and Ryan Seacrest), to see if the results varied by tone. They did not. Oh well.
I also tried to test this one by asking it to complete a handful of open-ended tasks, like writing a text to send a friend after beating them in the fantasy football championship, inviting a girl on a first date, or writing a joke for adults about forgetting your spouse’s birthday. I wasn’t sure how to score these though. An exercise left for future research, as they say.
Well, sorta. Most functions only worked with single-digit numbers. It only tried to deal with college-level numbers, like tweleve, on a couple occasions.
Is this all a joke? I think so? I hope so?
Enjoying the posts Benn! If you were wondering - ChatGPTs favorite Blaze Pascal quote:
"The heart has its reasons of which reason knows nothing."
You could turn this into a part 2 where you use ChatGPT to assess the differences in humans between being nice and being kind. Your neutral tone was kind because it was clear and direct. Be kind if you want to be more productive, be nice if you want to feel better. East coast vs west coast, North vs south, American vs European, SQL vs NoSQL... the possibilities are endless in the kind vs nice spectrum!