


The data hive mind senses a problem.
What started as a contrarian argument several years ago has, in the last few months, run a rapid course through the analytics community, turning from a spirited debate into derivative rehashes before quickly settling as resigned jokes about our unfortunate and potentially worsening predicament: We have too many tools.1
The data mess
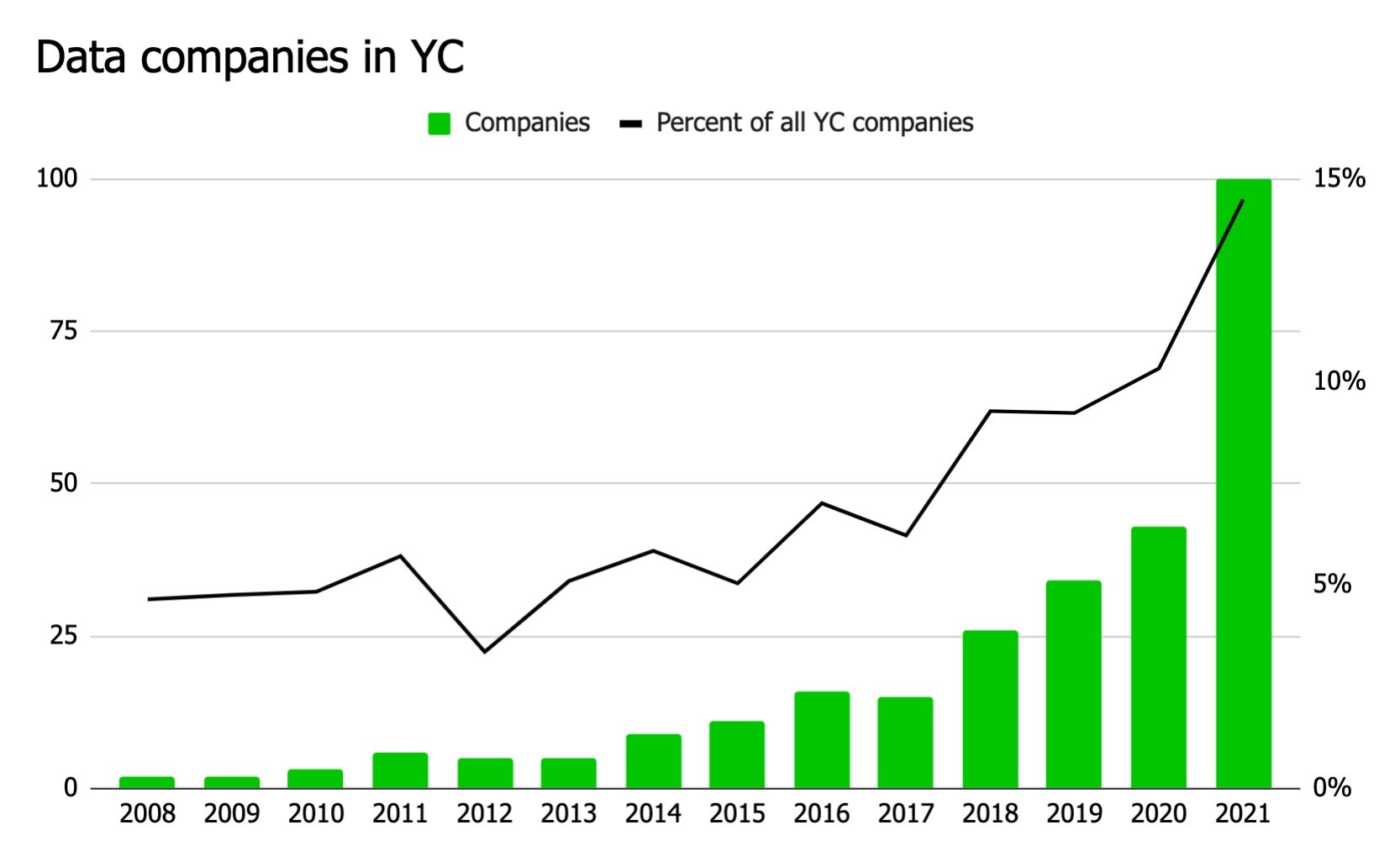
As data people, we definitely have a lot of tools. In 2017, Y Combinator—an incubator of both startups and the Silicon Valley zeitgeist—funded 15 analytics, data engineering, and AI and ML companies. In 2021, they funded 100.2 It’s impossible to make sense of this many tools, much less manage even a fraction of them in a single stack. As I said a couple weeks ago, fracturing our workflows into so many pieces is wrecking the experience of using the modern data stack.
Still, I’m not convinced that “too many tools” is the correct diagnosis. I also have a lot of apps on my phone. Despite that, it’s easy to manage, and new apps don’t disturb the careful balance of technologies on it.3
Though the analogy is far from perfect—there are lots of ways in which data tools aren’t mobile apps—it’s instructive in at least one way: On my phone, I don’t have to organize or integrate all of my apps with one another. The operating system keeps my library manageable. It catalogs my apps for me, sets standards for how they should behave, and facilitates clean interactions between them. If I download a new app, my phone’s OS fuses it into my existing collection and tucks the entire thing neatly away.
The data ecosystem functions quite differently. Buy a new tool, and you’ve got to shove others aside, jerry-rig4 some tenuous connections to the rest of the stack, and hope that the whole haphazard contraption survives long enough for you to band-aid it with the next product you stuff into it.
In many ways, this is the price of success. The dumbfounding valuations of companies like Snowflake and Databricks will keep attracting new entrepreneurs to found companies, keep attracting shotgun investors like YC to fund them, and keep attracting blank check firms like Tiger to float them. Unless the bubble bursts, culling or consolidating the ecosystem is a futile effort. Instead, we should try to figure out how to better manage the tools we have, and the shiny future ones we might want.
The data mesh
The current proposals for defending ourselves from tool overrun can be grouped into three categories. The first is extreme centralization. One vendor owns the entire stack, and bends every tool in their suite around the same central axis. Internal tools at Uber and Airbnb are built like this; cloud providers like GCP are gesturing in this direction, as are major data platforms like Databricks. Though I suspect offerings like these are inevitable, there will always be a large independent ecosystem of products that aren’t part of Microsoft’s or Amazon’s inventories. Plus, in an industry rooted in open-source technologies and committed to modularity, “let’s all submit to the mothership” is unlikely to be the slogan everyone rallies around.
The second solution is extreme decentralization. I’m not, to be honest, entirely sure what this means. As best I can tell, it’s a proposal for a shared open standard of communication between data tools, controlled by nobody but agreed to by everybody. While that sounds lovely, I’m skeptical we can pull it off. Data has long been a centralized asset, built for the boardroom down. Our historical starting point isn’t a commonwealth to unify, but a monolith of executive reporting to break apart. Moreover, the data ecosystem just isn’t that big. We probably don’t need a complex, fully decentralized system for figuring out how to make a few thousand tools talk to each other.5
The third proposal is a hybrid—and is best modeled by the now-infamous data mesh.
To quickly recap, the data mesh is built on two foundational ideas: Individual teams should manage and maintain their own data, and something—the mesh itself, I think?—should bring together and provide a unified view of these disparate datasets. Though the data mesh is often described as being decentralized, it’s not strictly so; teams that provide data don’t interact with each other directly, but do so through the centrally-managed mesh. And the standards of the mesh, which govern how data can be fed into it, are decided unilaterally by some central authority, presumably a data or IT team. This isn’t a decentralized architecture; it’s a delegated one.
This formal version of the data mesh doesn’t fix our tooling problem because it focuses almost entirely on how to design the data sources behind the mesh. What happens on the other side of the mesh, or even what the mesh actually is, isn’t discussed.6 But, if we apply the centralized-but-delegated model of the mesh more broadly, and extend it forward by both defining it more concretely and by considering how consumers use it, a compelling solution starts to take shape.
The data OS
Force me to describe how a data mesh might actually work, and my immediate thought is something like Trino (née Presto): It’s a query wrapper that sits on top of a bunch of data sources.
This seems to be the community’s best guess for well. But as Ross Housewright points out, this is an uninspiring answer. If the data mesh works with any underlying data structure (e.g., it can sit on top of BigQuery, Oracle, S3, and every weird thing in between), it doesn’t integrate anything. It’s just a switchboard, routing queries to different destinations.
If the data mesh does requires data sources to be heavily standardized (e.g., each data source is a Snowflake database configured in a particular way), the data mesh doesn’t do anything. It’s just another layer of organization above the database schema. Presto, in fact, already does exactly this.
In both cases, the data mesh fails to help people consuming data—the people for whom all of this effort is supposedly for.
These disappointments, however, highlight what a more ambitious approach could accomplish. What if, rather than just papering over the differences among its underlying data sources, the mesh resolved them? What if, rather than acting as a simple switchboard, the mesh provided common utilities for interacting with the data underneath it? What if, rather than being a filing cabinet for our data catalogs, the mesh served—as Android7 does to my phone—as the operating system for the entire data stack?
The data build tool
Nothing like this currently exists. But it almost does in dbt.
Today, dbt lives, incognito, inside of databases. Tools that use those databases interact with dbt’s products, but they don’t interact with dbt itself. They can only see dbt by its shadow.
As I said in a post about the metrics layer, this serves dbt well. It can slide into any data stack entirely on its own. No vendor needs to integrate with it, and, outside of the databases themselves, dbt doesn’t need to integrate with any vendor.
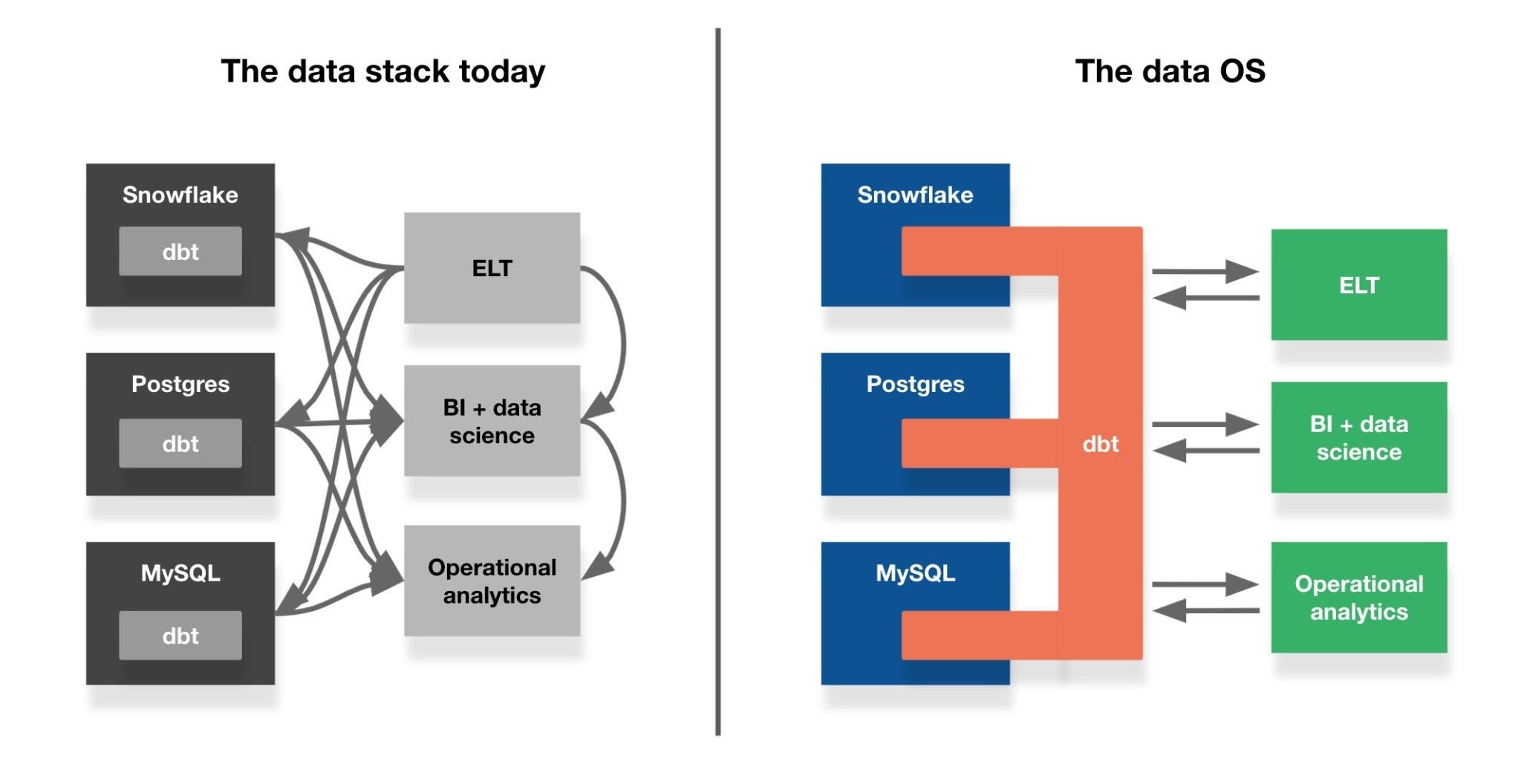
It could, though. Instead of just running silently inside of databases, dbt could also expose an outer edge for tools to connect to. This edge could not only provide access to the database (or, even, all the databases dbt’s in); it could also become a standardized platform for accessing, transforming, and governing data.
To extend the OS analogy, in this world, dbt is Android; the data is my phone’s hardware. dbt exposes the state of that hardware—schema information, the lineage of its tables, the latency of the data within them—to everything that uses it. Just as Android abstracts away the peculiarities of each device it runs on, dbt sands down the differences between BigQuery, Redshift, and others, providing a single language for interacting with all of them. Similar to how Android links apps together, dbt serves as a communications bus that, for example, pushes queries between a “production” environment in Census and a “development” environment in Mode. In the same way that mobile operating systems provide developers easy access to phones’ physical capabilities, dbt offers its own helper functions and syntactic sugar (e.g., what dbt enables with Jinja8) that shortcut and standardize common interactions with data.
Extend these ideas far enough, and entire apps could live inside dbt, doing everything from running on-the-fly tests against in incoming queries to finding and merging duplicative datasets across every tool and database in the stack.
In his recent post on the data mesh, Tristan (dbt’s CEO) said that we need to build a system organized around decentralized contracts, such that teams can work together with “no central authority governing the process.” While I admire the democratic ideal, I think we’d be better served if dbt took a more selfish approach. Just as every country doesn’t want to negotiate bilateral agreements with every trading partner, vendors don’t want to build integrations into every data tool. Central governing authorities—whether that’s the GATT, Android, or dbt—are sometimes exactly what’s needed. Convenience can be worth more than autonomy.
In my view, this is the most pressing problem the analytics industry faces today: How do we create, in a disparate ecosystem, a functional modern data experience? A data OS won’t get us all the way there, just as the Android operating system doesn’t make my phone great on its own. But it sure gets us a lot closer.
To solve this problem, I’m here to offer something we definitely don’t have a glut of: a Take.
True, this increase is partly explained by YC’s shift from elite incubator to cheap startup assembly line that tries to take a 7 percent stake in as many companies as possible in exchange for a handful of recut Zero to One lectures. Nevertheless, data companies are still growing as a percentage of total companies funded, from 6 percent in 2017 to 15 percent in 2021. And in any case, for those of us trying to make sense of all these products, the absolute number of companies building them matters more than a relative number.
New apps (read: TikTok) do, however, bulldoze my ability to tell the difference between a few minutes and an hour and a half.
Or it is, and I can’t figure it out.
Yes, I’m a proud green bubble, missing your texts, shattering your iMessage threads, degrading your videos into grainy 4-fps thumbnails that make the Zapruder film look like it was shot in 4k.
For what it’s worth, I have mixed feelings about Jinja. We don’t use it much at Mode because it’s difficult to debug and because queries that use it are no longer declarative. These issues aren’t endemic to dbt though; they’re because Jinja, which was built as an HTML templating language, was shoehorned into its current role. If dbt operated as an OS, Jinja could be more universally accessible (e.g., accessible inside of dbt and Mode), or could be replaced by something native to a SQL environment.
Isn't this, in essence, Denodo?
I like the analogy with an OS, but I doubt we will have something like this in the next couple of years, and even more skeptical of dbt's ability to pull this. dbt is a transformation layer with some cool things aside (based on ref it creates the lineage and processing dependencies, some minimal testing capabilities, and a couple more minor things related to deployment, snapshots), but it's a long shot to convert everything there is out there to dbt. dbt is still not suitable for real-time processing, having native transaction or procedural support, mutations, and many more. Oh and btw dbt does integrate today with lots of vendors (Airbyte, Fivetran, Hightouch, Paradime, etc.), and acts as the main hub. It's just is a small, limited hub :)
I think we should have an open protocol and enforce it on the big players (Snowflake,
BigQuery, Databricks). The protocol will define how each vendor will integrate and exchange data with other vendors and a suite of tests to pass for when you integrate. The underlying layer (OS) should be the cloud data warehouse platform, and every such platform to adhere to those standards.