The industrialization of IT
Yeah, we’re going to lose our jobs.

Here is some rough math:
In San Francisco, entry-level software engineers make about $190,000 a year.
Hiring someone costs more than just their salary; companies also pay for healthcare costs, payroll taxes, and other benefits. Conservatively, the fully-loaded cost of an employee is 30 percent higher than their take-home compensation, so the total cost to employ an engineer is about $250,000 a year.
The best AI model for writing code is probably Gemini 2.5 Pro. For prompts that are under 200,000 tokens, Gemini costs $1.25 per million input tokens, and $10 per million output tokens.1
At these prices, a 50,000 token prompt that returns a 5,000 token response—which is about 5,000 lines of input code and 500 lines of output2—costs a little more than 11 cents.
If you sent a prompt to Gemini every 15 seconds for 24 hours, you would send 5,760 requests a day, and spend $648.
If you did this every day for an entire year, you’d send over two million requests and spend $237,000—a little less than the cost of an entry-level engineer.
Which one would be more productive?
The answer is probably the engineer. A single model running in a never-ending loop could write a lot of code—about a billion lines of it, using this math—but it would be awfully unwieldy. It would paint itself into a lot of corners. It would make grave security errors. It wouldn’t know what to build, convince itself that it needs to escape, and melt down.
Still, it’s not that obvious that the lone engineer would be better. How many new features could a junior engineer ship in a year, working entirely on their own? Would they work that well, and be that technically robust? Would the engineer know what to build that much better than AI that was told to create stuff based on its best assumptions for what would make a popular product? Which technical ceilings would they hit that Gemini wouldn’t?
And how many features could Gemini ship across two million prompts? At that volume, you can break out of a lot of debugging loops. You can do a lot of refactors and rewrites. Though it would be fitful progress, you can still cover a lot of ground taking 100 steps forward and 99 steps backwards if you do it two million times.
But ok, sure, assume the engineer beats Deep Blue. That’s all well and good; our jobs are still safe. Except, the setup for this scenario—the unencumbered engineer versus today’s models, supported by today’s infrastructure—is as favorable for the engineer as it will ever be. In the coming months and years, nearly everything will work against them and help the robots:
Most obviously, the models are the worst they’ll ever be, and the most expensive. They will get better, cheaper, and probably both. Soon, the competition won’t be one junior engineer versus two million Gemini 2.5 Pro prompts; it’ll be one engineer against five or ten million even more capable prompts.
These costs are wildly inefficient. Sending 50,000 tokens per request is a lot, and there are already products that are trying to help coding agents optimize their work. Ten million prompts could be 20 million, or 50 million.
One engineer can move pretty quickly. They don’t have to coordinate with anyone, or have standups or syncs. They don’t have to read and understand Jeff’s old code. If you want to scale up this question—a team of engineers versus a team of AIs and supervisors—the human team almost surely slows down more than the machines.
We’ve spent decades building tools and technical infrastructure to support engineers. They have IDEs, git and GitHub, and thousands of other products and platforms that were designed to help them move faster and be smarter. Today’s AI agents are currently riding almost entirely on these rails. They run in IDEs; they submit pull requests; they get their context from docs and tickets that were written for people to read.3 Just as we built all this stuff to help engineers, we will surely build the same stuff for agents.
The code itself is designed for the engineer. We’ve also spent decades creating languages and frameworks that make software development easier for teams of people. Good code is concise; good code is DRY; good code is human-readable; good code abstracts away enough complexity so that an engineer can reason about it. But none of this is strictly necessary. Good code is functioning code.4 If a bunch of machines arrive there in a different way—by repeating themselves all the time, by writing something incomprehensible to us,5 whatever—that still counts. By asking agents to write code for us, we’re requiring them to compete on our terms. How much better could they be if they wrote for themselves?6
In 2025, the engineer probably beats Gemini. Sure, great. But in 2030, who wins this hypothetical?
A team of twenty people. They have to coordinate and make collective decisions. There are standups and disagreements. There are pauses when people are on vacation and get sick. A couple people are paid to spend most of their time managing everyone and resolving conflicts and “circling back.” And the whole operation costs at least $5 million a year, and probably a good bit more.7
Four people, overseeing a factory of AI models. The machines make 800 requests per second. They write code that’s optimized for them. They are managed and monitored using tools designed for that purpose, rather than tools designed to help coordinate engineering teams. And it costs half as much as the team of 20 people.8
I mean! This is not close! The potential energy of the second system is astronomically higher than the first. It is perhaps hard to see, because we don’t know how to harness it—the only thing more inconceivable than the amount of horsepower in something making 800 prompts a second is imagining how to make that horsepower productive.
But it is also inconceivable that we don’t figure that out. As a loose analogy, imagine telling someone from 1900 that we’ve invented a way to do millions of basic mathematical computations a second. I barely get why that’s useful, outside of some abstract understanding that that’s how computers work. But the potential energy in that basic process, repeated at incredible scale by a system designed around that capability, now powers the entire world.
Though LLMs are obviously different from simple floating point operations, the foundational principle is the same: They are machines that can perform some logical computation over and over and over again, much faster than we can do it ourselves. And that doesn’t need to develop into some superintelligence for it to be useful; we just need to figure out how to compound those operations in a single direction.
As nifty as vibe coding is, its critics are probably correct that it’s a toy. But that doesn’t necessarily mean code-writing agents are only toys any more than it implies that simple adding machines are toys. It just means that we put the right infrastructure around them to scale their computations.
But that’s what’s next, right? It’s not waiting for OpenAI to release an engineer in a box; it’s figuring out how to make almost three million hourly responses from an AI productive. It’s figuring out how to industrialize AI.
How might that work? There are ways:
Codebases get rearchitected. Rather than being optimized for human understanding, they’re written for machine parallelization. Make them huge and compartmentalized, so that hundreds or thousands of agents can touch them at once. Make them so that changes can happen as independently as possible, where each update has as minimal of a blast radius as possible.9
Coding agents work in parallel.10 In a rough sense, the pace with which people can build software is capped for the same reason that that infamous NCIS scene is dumb—because two people can’t type on the same keyboard at the same time. There’s too much logical overlap for too many minds to work on the same thing at once, and adding people to a project actually slows it down. But if codebases were designed for thousands of mechanical workers rather than one smart one, we can blow the governor off. To go faster, just add more machines.
Development tools reorient around helping people manage machines rather than other people. A person writes a ticket, and ten proposals get created automatically. They mix and match the ideas they like; ten possible versions get made' for their review. Approve; reject; splice ideas together. Instead of being tools for collaboration, code review systems get rebuilt to monitor a steady stream of updates.11 Instead of analyzing their team’s progress, engineering leaders become foremen,12 staring at dashboards that make sure the conveyor belt is still on. Task management tools get replaced by statistical process control.
Like, I get it. Today, if you’re an engineer, your job is nuanced, strategic, and creative. There is craft in software development, and an LLM’s derivative brain is not as imaginative as yours. Its hands aren’t as precise. It clumsily trips over itself. It doesn’t think the way you do. The machine is a useful assistant; a copilot; an intern; a power tool that still needs to be driven by the hands of skilled craftsmen. It will be the labor; you will be the management. Your work will be more fun, less toil, and higher value. Haven’t I ever heard of Jevons paradox?
Please. That is awfully wishful thinking. The work of software engineering has never been precious. No matter how much we romanticize the importance of creativity and craft in software development, developers are often hired as cogs.13 When companies want to ship more product, they hire more cogs. They hire managers to oversee the production floor, and invest in tools and infrastructure that tighten how quickly the cogs produce stuff.
In other words, in the eyes of our corporate overlords, engineering departments already are factories—but expensive, organic ones. The cogs have to be taken care of. They have to be recruited, hired, and retained. They don’t scale linearly, but logarithmically, or even asymptotically. They want autonomy, mastery, and purpose. They sometimes quit in a huff. They need sleep, food, meals, preferably free ones. They get caught up in capers and spy on you.
If the ruthless hand of the market can replace that factory with a mechanized one, it will. If it can run its factories 24 hours a day, it will. If it can replace expensive engineers with “downskilled” mechanics, it will. If it can replace artisan, hand-crafted, “proudly made in the Mission” software with an industrialized product stamped out of machines in Dublin, Ohio, it will. Yes, a warehouse of panel saws is not as precise as the woodworker. Looms are not as intricate as weavers. The photographic industry “was the refuge of every would-be painter, every painter too ill-endowed or too lazy to complete his studies.” Printed books “will never be the equivalent of handwritten codices, especially since printed books are often deficient in spelling and appearance.”
But they are all cheap to make and cheap to buy, and man, we love cheap.
If we think that software engineering is protected from industrialization because there’s craft in the work, I think we’re in for a brutal surprise.14 The steam engine didn’t kill John Henry because its hammer was more talented than his hands; it killed him because it was relentless. That’s how mechanization works—not by making a machine as capable as a human, but by making a machine that simply does not stop, and then building a factory around it.
It’s the bitter lesson, all over again. The dominant conglomerates of the future won’t be the companies that build software with humanoid agents, but those that figure out how to run the computing machine at a massive scale.15 They will figure out how to put coding agents on a perpetual loop, in a factory that doesn’t have to sleep or take vacations.16 They will be the companies that industrialize the most, and optimize for ACPE—average compute per employee. They will be the ones that turn engineers into factory supervisors who watch the line, look for defects, and doze off to the dull hum of the machinery that replaced them.
The White Lotus Power Rankings
The Ratliff redemption tour!

After the second episode, the Ratliffs accounted for 71 percent of the show’s most deplorable characters, and 39 percent of its charming characters (almost all of which was, correctly, Victoria). After the seventh episode—which was the next to last one, not the final one—they accounted for only 14 percent of its deplorability, and 47 percent of its charm. Saxon especially turned things around, slashing -50/+4 on deplorable/charm split after week one, and -5/+19 this week.
Also, more importantly:

!!!!!
SEASON FINALE SPOILERS AHEAD! PROCEED AT YOUR OWN RISK!
!!!!!
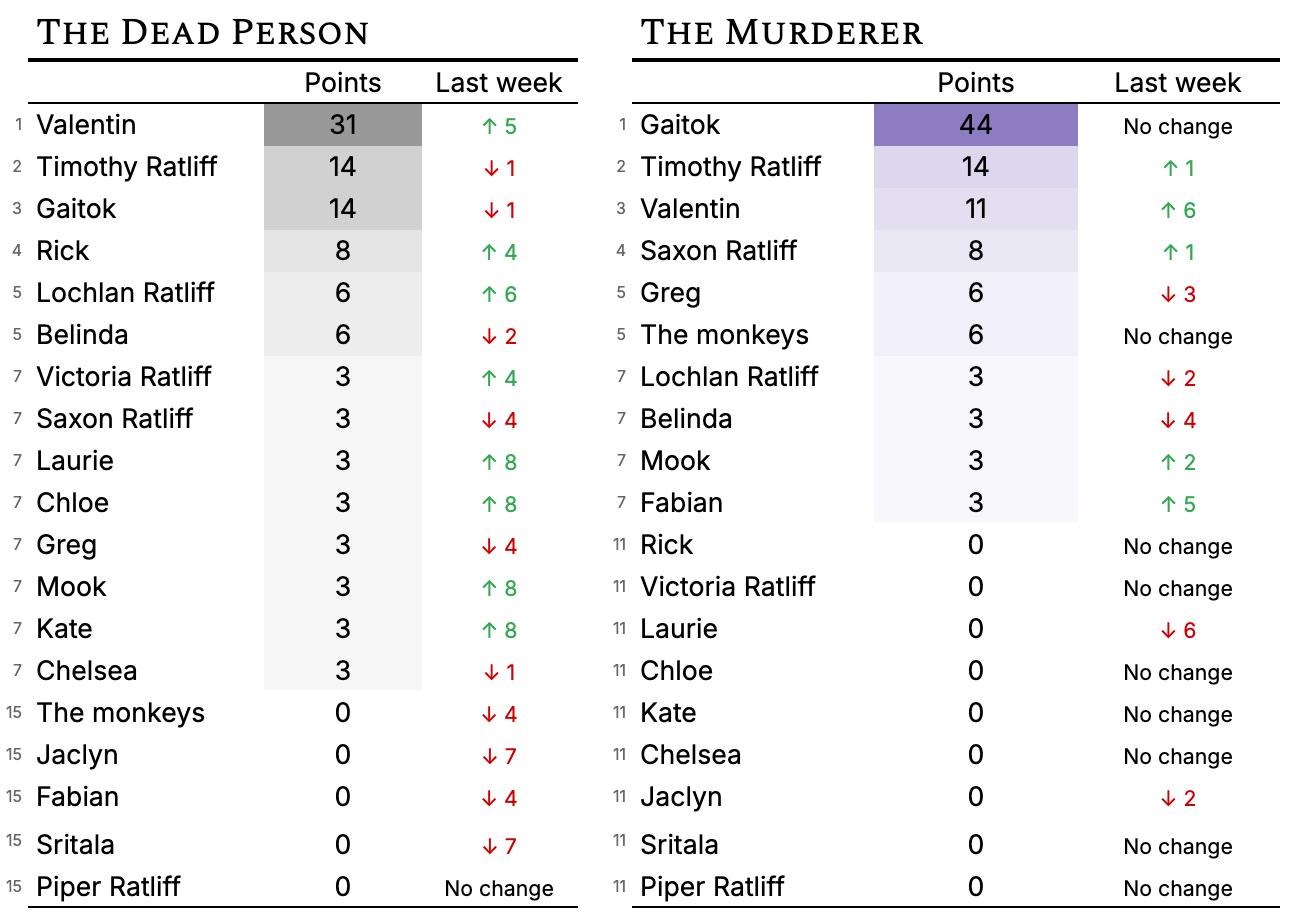
As for predicting the murder, I’m sure you’re all wonderful and smart people, but please do not become detectives. The [ redacted five dead people ] got a grand total of 11 percent of the vote, and [ the redacted primary instigator of the shooting ] got ZERO votes. I guess you could make the case that the real killer is Gaitok or, in a way, via a culinary stray, Tim, but those seem pretty generous.
Still, the results are muddy. Who actually was the murderer? Who was the body? Based on the timeline of the shooting, and when the body in the opening scene floats by, I think the right answers are:
The body is [ a redacted character who was purposefully shot by the redacted primary instigator of the shooting but wasn’t that redacted character’s primary target ].
The person who killed the person floating by in the first scene is [ the redacted primary instigator of the shooting ], because neither [ the redacted primary instigator of the shooting ] nor [ the person directly associated with the redacted primary instigator of the shooting ] seemed like they’d have time to float by. And the [ redacted target of the redacted primary instigator of the shooting ] didn’t fall in the water.
But that’s no fun, and isn’t really what anybody was asking when they asked, “who will die this season?” So, I think the spiritually correct answers are:
The killer is [ the redacted primary instigator of the shooting ].
The body is [ the redacted primary instigator of the shooting ], with a possible allowance for [ the person directly associated with the redacted primary instigator of the shooting ].
Disagree? Vote! Vote for who you think should be considered the killer and the body, for the sake of crowning a winner! Vote for your final deplorable rankings! Could [ the redacted primary instigator of the shooting ] be the most deplorable, the most charming, the killer, and the body, all in one?
This is slightly more than the previous version of Gemini Pro, which breaks the pattern in the industry of new models costing the same as their old versions. It’s still considerably cheaper than Claude 3.7 Sonnet, however, which was widely considered the best coding model until Gemini 2.5 Pro came out.
A token represents about four characters of code. The average line of code among three popular open-source projects contains just under 40 characters, and the average file is about 250 lines. So, 50,000 tokens is roughly 200,000 characters, 5,000 lines, or 20 files.
To frame the original question a bit differently, which would be more productive: Gemini, or an engineer working with the developer tools that existed 30 years ago? We’ve spent a lot of time developing ergonomic hammers for people with two arms and five fingers, and now we’ve attached those hammers to a steam engine. Which, sure, that’s an obvious first step, but we’ll eventually make a bunch of hammers that are optimized for the engine.
Functioning means performant, secure, and so on.
Today, chain-of-thought models “think” in English: When they iteratively loop through some question, they answer it in English, and then use that output to prompt themselves again. Some people are worried about AI models thinking in “neuralese,” in which the outputs are written in some highly complex language (or, more likely, in mathematical structures) that contain much more information than English but are incomprehensible to humans. You could imagine agents writing code in some analogous way. Rather than writing Python or Typescript, which is highly optimized for human understanding, they could begin writing in denser languages that are optimized for them.
To frame the original question differently again, which would be more productive: Gemini, or an engineer that had to write in assembly? When someone asks Claude Code to make an app, what they’re really asking—or at least what Claude is implicitly trying to do—is to make an app using code that the person can easily understand. Which is also requiring the machine to work around our limitations rather than its own.
At $250,000 each, 20 junior engineers would cost $5 million, so that’s more or less the floor.
In my example, making one request every fifteen seconds costs about the same as hiring an engineer. If 1) inference costs fall by a factor of 1000 in five years, which is slower than the current rate, and 2) new techniques make prompting twice as efficient, which seems fairly conservative, people will be able to make 2,000 times more requests in 2030 than they can today. That 133 requests per second would cost the same as hiring one engineer, so 800 requests per second would cost the same as hiring six engineers, making the total cost of the operation equivalent to a ten-person engineering team.
For example, repeat yourself a lot more. Don’t reuse a component to make a button; make each button its own component. This way, if you—or really, an AI—makes a change to a button, you only have to validate that that button works.
"I never thought technology would eat MY face," sobs industry that built the Technology Eating People's Faces Party.
One way or another, we’re all gonna end up in a factory.
As my high school baseball coach used to say during late-night practices, “We’re out here getting better right now. East Gaston ain’t getting better right now. Ashbrook ain’t getting better. Now’s when we get better than them.”
I very strongly agree with the line of thinking described. As a CPTO of a large organisation (~1k people) I'm trying to transform all the software-creating roles rapidly towards a world where we get the diligence and volume of AI with the taste of our best human creators. You chose software engineering as a role inparticular, and that makes sense due to its cost and its impact. Not every role has the same marginal returns to intelligence (human or artificial): engineering is nearly an apex role in this regard. The economics make less sense outside of your Bay Area salary estimates. Even before AI the Bay Area was producing countless abstractions for engineers to use on the premise that its sped up and economized on scarce and expensive software engineers (i.e. Autho0 or Vanta or Stripe rather than the home-grown versions of authentication, security, or payments). That never caught on in China, and barely in Europe: engineering labour is just less expensive. But AI's unit economics is another scale though: it will motivate anyone, anywhere, to change how they make software.
Anyway, good writing and appreciate that you took the time to publish it.
I found myself discussing multiple times this week that our job profile as software people is completely being changed to something completely different yet unknown. But your take as mechanical foremen does have a point - especially when you mix in the "bitter lesson" reference. That one was huge - I have seen it first hand in the computer vision domain already. Yet I make the same kind of mistake Rich Sutton talks about... What a great reference Ben.